段错误——关于计算机内存布局
去年我花了一段把整个计算机体系结构方面的知识复习了一遍,当时发现我们对于内存体系存在很多误解,例如很多人(不乏一些技术还不错的人)认为虚拟内存只是物理内存的扩展,它的作用是在物理内存不够用的时候把部分内存中的数据保存到磁盘的交换分区中,这个是完全错误,而且错得很离谱,所以我一直希望能够写一篇介绍虚拟内存方面的文章,最近我无意中发现了Julien Pauli的这篇文章,个人感觉写得非常不错,而且考虑到自己没有写出这种文章的水平,所以干脆不如把它翻译出来,希望这篇文章能够帮助你更全面正确地理解内存布局方面的基础知识。
段错误(Segmentation fault)
“段错误”这个词就是这篇文章的主题,在此我将以拨洋葱手法逐步给你呈现这个词的含义,以及为什么会出现这种错误。
如果你写过一些C程序,那么相信你对“segmentation fault”一定不会陌生,这是程序运行中出错所输出的错误消息,多是以“segfault”的简写形式出现,而且大多数时候都伴随着程序崩溃。我记得以前我在写C程序的时候,我的同事和经理经常会带着一脸坏笑突然出现在我面前:“哈哈,我们又发现了一个segfault。”,此时我只能无奈地承认:“好吧,我会处理的。”。收到“段错误”的消息确实并非什么愉快的消息,但是,我希望你扪心自问一下,你真的理解“段错误”的含义么?
先友情提示下,以后我可能会写一些跟PHP内存相关的技术文章,所以如果你能够先搞清楚一些内存方面的基本概念,相信到时候你读那些文章的时候会更顺畅,而这篇文章就是帮你理清一些内存方面的基本概念的。
我们现在回到上面的问题,要回答这个问题,我们要先把时间倒回到1960年代。我将讲解计算机是怎么工作的,或者更准确地说是现代计算机是怎么访问内存的,然后你就会理解这个奇怪的消息是从何而来的。
我会给你呈现一些计算机体系结构方面的知识,如无必要我尽可能不深入扩展,并且会尽可能使用已被广泛使用的术语,这样每个从事计算机方面工作的人都可以理解这些跟机器如何工作相关的重要概念。
当前市面上有很多讲解计算机体系结构的书籍,如果你想更深入地了解这方面的知识,那么我建议你去搞几本书读读。另外也可以去阅读操作系统的内核代码来学习这些知识,例如阅读Linux内核源代码,当然阅读其他操作系统的内核源代码也可以。
我不会在这篇文章中详述历史,这篇文章的目的是希望以尽可能简单直接的方式把问题讲清楚,所以它不会覆盖计算机体系结构的所有方面的知识,有些部分是没有触及的,还有些部分是经过(极大地)简化了的。
一些历史知识
在1960年代,计算机非常庞大,都是以吨为单位。在这些庞然大物中,你可以发现一个CPU,以及一块内存(RAM),大小是16Kb。我们不可能追忆更久远的历史,那都是在CPU芯片时代之前的上古时代了。
在这段时期,一台计算机大概需要150, 000美元,而且一次只能执行一个任务:在某个时间段内只能运行一个进程。如果我们想把这种计算机的内存布局用一个草图来表示,那会是下面这个样子:
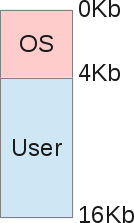
如你所见,这个内存的大小是16Kb,在16Kb的内存中存了两个东西:
- 操作系统(OS)内存区域,占4Kb(假设)
- 正在执行的进程的内存区域,占剩下的12Kb(假设)
那个时候的操作系统的主要工作就是利用CPU中断来简单地管理硬件。所以操作系统自身也需要占用内存,例如把某个设备中的数据拷贝到内存中然后再处理它们(PIO模式)。仅仅只是在显示屏上显示几个字符也需要一些主存,在那个年代,视频芯片组也可能会占用一部分内存区域(译注:视频芯片组就是显卡,实际上显卡的显存一直都是从主存开辟一块区域,只是独立显存出现后才没有再占用主存)。
从这个图来看,程序运行中所占用的内存是紧挨着操作系统的内存,程序就是在这块内存中完成它的工作。
ok,现在我们已经搞清了古时候的计算机的内存布局。
共享机器
上面所介绍的模型的最大问题是这种机器(价值150, 000美元)一次只能执行一个任务,这个任务可能要运行很长时间:运行一次要几天的情况很常见,并且它只能处理几Kb的数据。
一台机器这么贵,所以没人愿意为了能同时处理多个任务而去买多个机器,所以大家只能设法让多个任务能够共享机器的资源从而实现同时运行的目的。多任务就是这么诞生的。当然我们现在不会讨论一个台机器多个CPU情况。我们怎么才能让一台机器在只有一个CPU的前提下同时处理多个任务呢?
答案是进程调度(scheduling):当一个进程通过一个中断等待I/O的时候,此时CPU就可以运行另外一个进程了。在此我们不会讨论进程调度方面的东西(这个课题太大了),我们只谈论内存。
如果一台机器可以同时处理多个任务,那么这也意味着要修改内存的布局,现在变成了下面这个样子:
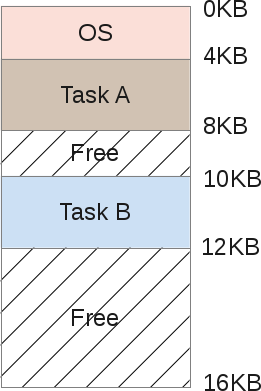
任务A和任务B所需要的内存都会存在于RAM中,我们不可能把部分数据存在磁盘上,这是因为在内存和磁盘之间不断拷贝数据是一个非常耗时的工作,所以只要这个任务还处于运行状态中,它所需要的数据必须永久地存在于RAM中。
这看起来似乎不错:调度器(scheduler)先分给任务A一些CPU时间,然后再分给B一些,这种不断交替。每个任务每次都只访问各自的内存区域。不过这样似乎还有一个问题。
如果某个程序员编写了任务B的代码,那么他必须先知道任务B的内存区域的地址界限。以上面的任务B为例,它所占的内存区域是从10Kb到12Kb,所以程序中用到的任何地址都必须得硬编码为这个区间的地址。不过如果这个机器要运行3个任务,那么整个地址空间(address space)必须得重新分配,跟任务 B相关的内存区域可能需要移动,那么任务B的程序员就需要改写它的程序了。最终我们为了减少每个程序运行时占用的内存量从而保证一次可以运行多个程序,而不得不在程序每次运行之前先重写它的内存指针地址。
这里还有另外一个明显的问题:如果任务B访问了任务A的内存呢?根据上面的模型,这种情况很容易出现,因为你可以操控指针,所以一个小的计算错误就会导致访问一个完全不同的内存地址:任务B可以访问任务A的内存并且可以通过覆盖这个地址对应的内容使任务A崩溃。这也会导致安全问题:如果任务A是一个非常敏感的程序,并且使用非常敏感的数据?这里没有办法可以阻止任务B读取任务A内存区域的数据。还有一种更令人蛋疼的情况:如果任务B的代码有问题,它在运行的时候覆盖了操作系统内存区域的内容呢?在这个模型中,从0Kb到4Kb是操作系统的内存区域,如果任务B覆盖了它,那么操作系统必然会崩溃。
内存空间
所以,为了能在内存中存在多个任务同时运行,操作系统和硬件必须提供更多的帮助。首先创造了一个名为地址空间(address space)的东西。地址空间是对操作系统可以分配给一个进程的内存区域的抽象,这是一个非常基础性的概念。现如今,你在生活中碰到的任何计算机(或者是使用了计算机的东西)都是基于地址空间设计的,除此之外没有其他的内存模型(也许军方有一些秘密研究吧),你使用的个人电脑,你的手机,你的电视,你的游戏机,你刷卡的机器,以及你可能会像个2B一样跟它们说话的眼镜或者手表。
如今的任何一个计算机系统的内部都是以代code-stack-heap(代码-栈-堆)的内存布局的形式组织的。
内存空间包含了一个任务(进程)运行所需的所有东西:
- 它的代码: CPU将执行的机器指令
- 它的数据: 机器指令执行时所需要的数据
地址空间可以被划分为下面这个样子:
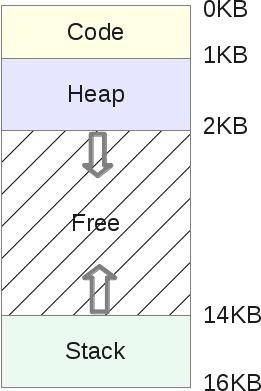
- stack(栈)是一块用于保存函数调用信息——传递的参数、每个函数的本地变量的内存区域
- heap(堆)是一块程序可以任意使用的内存区域,程序员有完全自由的权限对这个区域进行任何想要的操作
- code(代码)是一块用于存放可执行程序的CPU指令的内存区域。这些指令都是由编译器生成的,当然也可以完全手写。另外需要说明的是代码段(code segment)通常会分为三个部分(Text、Data和BSS)(译注:这三个段分别是文本段、数据段和未初始化数据段,每个部分的具体含义请自行搜索),这篇文章不会对它的每个部分做进一步介绍
- code部分的内存大小是固定的,在上面的图中我们把它设定为1Kb
- stack部分的大小在程序运行过程中是可变的。当函数调用发生时,stack就会扩大,当函数调用结束时:之前扩大的stack就会缩小为调用之前的样子
- heap同样也是一个大小可变的区域,当程序员从heap中请求内存(malloc())时,heap就会扩大,当这些内存被释放后(free()),heap就会缩小。
stack和heap都是可伸缩的区域,它们处于整个地址空间中的相对位置:stack会向下扩展(由高地址到低地址),而heap则会向上扩展(由低地址到高地址)。它们都是可以自由增长的区域,只是增长的方向刚好相反。操作系统只需要检查这两个区域不会出现重叠的情况,这是它们主要的使用限制。
内存虚拟化
如果任务A获得了一个上面所描述的地址空间,那么任务B呢。。。我们怎么把它们同时安放在内存中呢?这看起来似乎很奇怪。任务A的地址空间从0Kb到16Kb,任务B也是如此。是不是有点晕了:)
之所以能够这么做,是因为这里还使用了一种叫做虚拟化(virtualization)的技术。
我们先回看一下A和B同时处于内存中的情况:
当任务A想访问它自己所在地址空间中某个地址的内存时,我们假设这个地址为11K,这个地址可能位于它自己的stack中,此时操作系统必须设法避免加载地址1500处的内存,因为在内存中,地址11K是属于任务B的内存。(译注:个人感觉这段话的意思非常难以理解,这个1500的地址不知道是怎么跑出来的,而且为什么又要避免访问这个地址对应的内存,完全无法理解,我大概揣摩下作者的意思:任务的虚拟地址空间是0~16K,而任务B的虚拟地址空间也是0~16K,两个任务都可以访问各自所有的虚拟内存,所如如果我们是将虚拟内存跟物理内存进行直接映射的话,那么任务A访问11K地址的内存,从上图来看将访问任务B的内存,这显然是不行的,大概是这个意思,1500完全不知道是怎么跑出来的)
任何一个程序都会把分配给它的整个地址空间当作属于自己的内存,这实际上只是虚拟内存(virtual memory),所有一切都是幻觉。在任务A的内存中,地址索引11K处的内存,只是一个假的地址,这是一个虚拟内存地址(virtual memory address)。
任何在机器上运行的程序都只是与假的虚拟内存打交道。在一些硬件芯片的协助下,操作系统可以让进程以为它可以访问任何区域的内存。
操作系统会对内存进行虚拟化处理,并且可以确保任何一个任务都不能访问不属于它的内存:内存的虚拟化实现了进程的隔离——任务A再也不能访问任务B的内存了,也不可能访问操作系统的内存了。并且这一切对于用户级的任务都是完全透明的,这都是源于复杂的操作系统内核。
从上我们可以看到,操作系统会负责处理每个进程的内存需求。它必须表现得非常高效——这样才不至于影响其他程序的运行速度——要达到这个目标则需要硬件的帮助:主要是通过CPU和CPU周围的一些电子设备来实现的,例如MMU(Memory Management Unit,内存管理单元)。MMU出现于70年代,IBM创造的,当时是一组独立的芯片。现在它们已经被直接嵌入到CPU芯片中了,并且对于任何现代操作系统而言,它都是必须的。实际上,在这种模型下并不意味着操作系统就要做很多事情,这里的很多工作都会依赖于一些硬件来实现,这会使内存访问变得更容易。
下面是一个简单的C程序,这个程序会输出一些内存地址:
#include <stdio.h>
#include <stdlib.h>
int main(int argc, char **argv)
{
int v = 3;
printf("Code is at %p \n", (void *)main);
printf("Stack is at %p \n", (void *)&v);
printf("Heap is at %p \n", malloc(8));
return 0;
}
在我的LP64 X86_64的机器上,输出的结果为:
Code is at 0x40054c
Stack is at 0x7ffe60a1465c
Heap is at 0x1ecf010
我们可以看到stack所在的地址要比heap所在地址高很多,并且code所处的地址位于stack之前,正如我们之前所描述的。
不过这三个地址都是假的:在物理内存中,位于地址0x7ffe60a1465c处的内容绝对不会是一个值为3的整数。请切记,任何用户级的程序(user-land program)只能操作虚拟内存的地址,而且只有内核级的程序(kernal-land program),例如操作系统内核本身或者是硬件驱动(译注:实际上硬件驱动的代码都是位于内核中的)才可能直接操纵物理RAM的地址。
转换地址(Translating addresses)
地址转换(Address translation)是一个专用术语,它用于描述用户级程序的虚拟地址到物理地址的转换,这个工作是由硬件(例如MMU)完成的。
因此操作系统必须记住每个正在运行的任务的每个虚拟地址跟它所映射的物理地址的对应关系,这个工作很有挑战性。操作系统必须得管理每个用户级任务的每一个内存访问需求,从而可以保证让这个任务一直处于独享整个内存的幻觉之中。因此最终操作系统会把物理内存是有限的这个残酷的现实转换为一种有效、强大并且简易的抽象。
我们来通过一个简单的场景来详细讲解下这个过程。
当一个进程被加载时,操作系统会为它预留一段固定的物理内存区域,我们假设是16Kb。操作系统会首先将这段空间的起始地址保存在一个特殊的变量里面,这个变量被称为base(基址)。然后再设置另外一个特殊的变量,这个被称为bound/limit(界限),它保存的是整个空间的大小:这里是16Kb。操作系统会把这两个值保存在每个进程的进程表中,这个进程表被称为PCB(Process Control Block,进程控制单元)。
下面是一个进程的虚拟地址空间:
下面是它的物理映像(image):
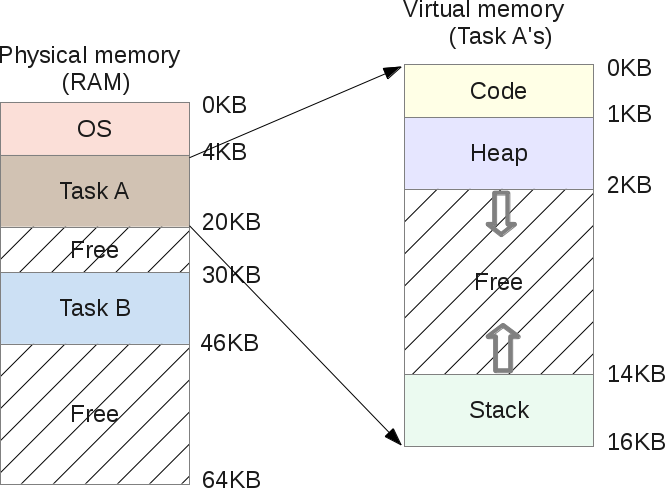
操作系统选择将任务A存储在地址从4K到20K的物理内存区域内,因此它的base会被设置为4K,并且bound会被设置为4+16=20K。当这个进程被调度(分配一些CPU时间片)时,操作系统会从PCB中读取base和bound,然后把它们拷贝到CPU的寄存器中。然后这个进程就会开始执行,并且会加载虚拟地址为2K处的数据(可能是位于它的heap中),CPU会把这个地址与从操作系统获取的base相加。这样这个进程的内存访问就会被导向到物理地址2K+4K=6K处。
物理地址 = 虚拟地址 + 基址
如果计算出的物理地址(6K)不处于地址界限(4K~20K)之间,这表示这个进程正在访问一个不属于它的无效地址:此时CPU会抛出一个异常,如果操作系统已经设定了对应的异常处理程序(exception handler),那么操作系统会被CPU唤醒,并且知道CPU刚刚发出了一个内存异常。它的默认行为是给出错的进程发送一个信号(singal):SIGSEGV——段错误(Segmentation Fault),并且默认会终止这个任务(这个行为可以修改):这个进程由于不合法的内存访问而终止。
内存重定位
如果任务A被调度出(unscheduled)CPU,这是因为调度器被要求立即运行另外一个任务,假设是任务B,当运行任务B的时候,操作系统可以自由地重新定位分配给任务A的整个物理地址空间。在一个用户级任务运行的过程中,操作系统也经常会获得一些CPU时间,这通常会发生在用户级任务发出了一个系统调用(system call)的请求,此时对CPU的控制会被交还给操作系统,在操作系统完成系统调用之前,它可以在内存管理上做任何它想做的事情,例如把某个进程的地址空间重定位到另外一块物理内存区域中。
这对于操作系统而言很好处理:它只需要把之前的16K的内存区域移到另外一个空闲的16K的内存区域,然后简单的更新下任务A的base和bound。之后当这个任务再次获取CPU时间并重新恢复运行时,之前的地址转换处理依然可以正常工作,只是现在导向的不是之前的物理地址而已。
从任务A的角度来看,它不会注意到任何变化,它自己所拥有的地址空间仍然是从0K到16K。操作系统和MMU接管了任务A的任何一次内存访问,这会一直维护任务A独享整个内存的幻觉。编写任务A的程序员只能操作所被允许的从0K到16K的虚拟地址,隐藏在后面的MMU会负责把所有的内存访问导向到正确的物理内存。
当我们上面所说的重定位发生后,现在的内存映射看起来会变成下面这个样子:
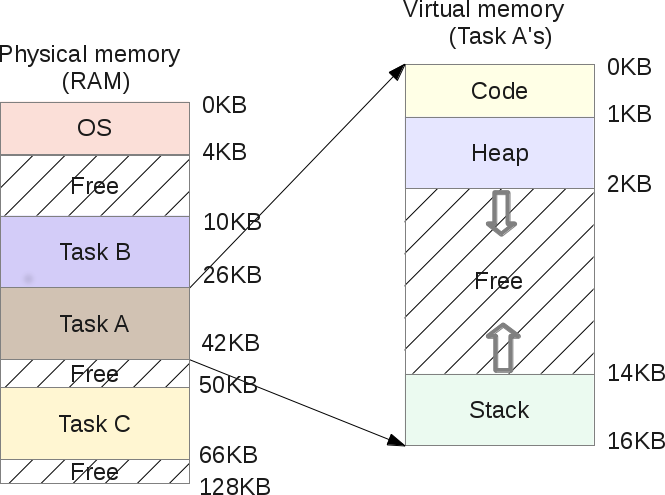
对内存的编程现在变得更容易了:程序员不需要再关注它的程序会被加载到RAM的那个位置,如果另外一个任务会挨着他的任务运行,那么这个任务可以操作哪些内存地址呢:这是由操作系统亲自控制的,并由一些非常高效和智能的硬件协助:内存管理单元(MMU)。
内存分段(Memory segmentation)
你可能已经注意到我们已经提到了“segmentation”这个单词:这意味着我们已经接近“为什么会产生段错误?”这个问题的答案了。
在上一章,我们已经搞清楚了地址转换和重定向,但是我们所使用的模型依然存在一些缺陷:
- 我们假设所有的虚拟地址空间都是固定的16Kb大小。这显然不是现实中的情况。
- 操作系统必须维护一份空闲的物理内存槽(slots)的列表,每个槽的大小为16Kb,这样在新进程启动的时候可以直接从这个列表中取出一个内存槽分配给这个进程使用,或者是在进程恢复运行时进行重定向。这里存在的问题就是如何快速完成这些工作以至于不会拖慢整个系统的运行?
- 你也可以观察到每个进程的内存映射都是16Kb大小,即使是这个进程没有完全使用整个地址空间,这是很有可能发生的情况。在这种情况下,很显然这个模型会浪费不少内存,例如如果某个进程在运行过程中实际只使用了1KB的内存,但是系统确为它分配了16Kb的物理内存,剩下的15Kb显然就完全被浪费了。这种浪费被称为内部碎片(internal fragmentation):内存已经分配给了进程,但却从来没有被使用到。
为了解决这些问题,我们需要了解操作系统中一种更复杂的内存组织模型:分段(segmentation)。
分段很好理解:我们只需要把“base and bounds(基址和分界)“的概念扩展到内存中的三个逻辑段(logical segments):heap(堆)、code(代码)和stack(栈),这样每个进程就不用把内存映射当作一个整体来考虑了。
这样之前在stack和heap之间会被浪费的内存现在就不会出现了。如图所示:
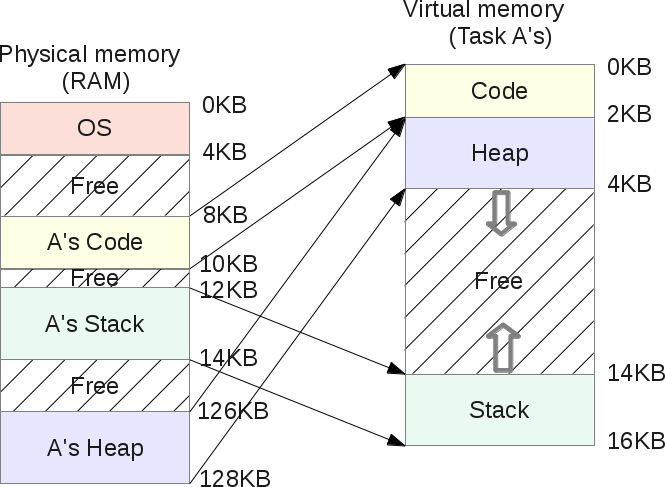
从这个图中我们可以很容易发现任务A的虚拟内存中的空闲区域并没有分配对应的物理内存,此时对内存的使用变得更有效了。
现在对于每个任务而言,唯一的不同之处是操作系统不能只记录一对base/bounds(基址/界限)的值了,现在需要记录三组:每个段需要记录一组。地址转换还是由MMU负责,转换的方式跟之前一样,只是现在会支持3个base和3个不同bounds。
以上图所展示的情况为例,任务A的heap的base为126K,它占的大小为2K,所以bounds为126K ~ 128K(126K+2K)。所以如果任务访问3K的虚拟地址,这个地址位于它的heap中,对应的物理地址就是3Kb - 2Kb(heap的起始虚拟地址)= 1Kb + 126K (基址偏移)= 127K。127K位于126K ~ 128K之间,这是一个有效的内存访问。
段共享(Segment sharing)
对物理内存进行分段不仅解决了为空闲的虚拟内存分配多余的物理内存的问题,同时还带来了另外一个好处,那就是可以在不同进程的虚拟地址空间中共享物理段。
如果你两次运行同一个程序,它在内存中将以两个任务的形式存在,我们假设运行的是任务A的程序,那么这两个任务的代码段是完全相同的:它们所执行的CPU指令是完全一样的。不过这两个任务会有各自独立的stack和heap,因为它所使用的数据集是各自独立享有的,在这种情况下没有必要在物理内存中保存两份代码段的内容。现在操作系统可以处理这种共享,这样就可以节省更多的内存。此时内存的布局变成下图所示的样子:
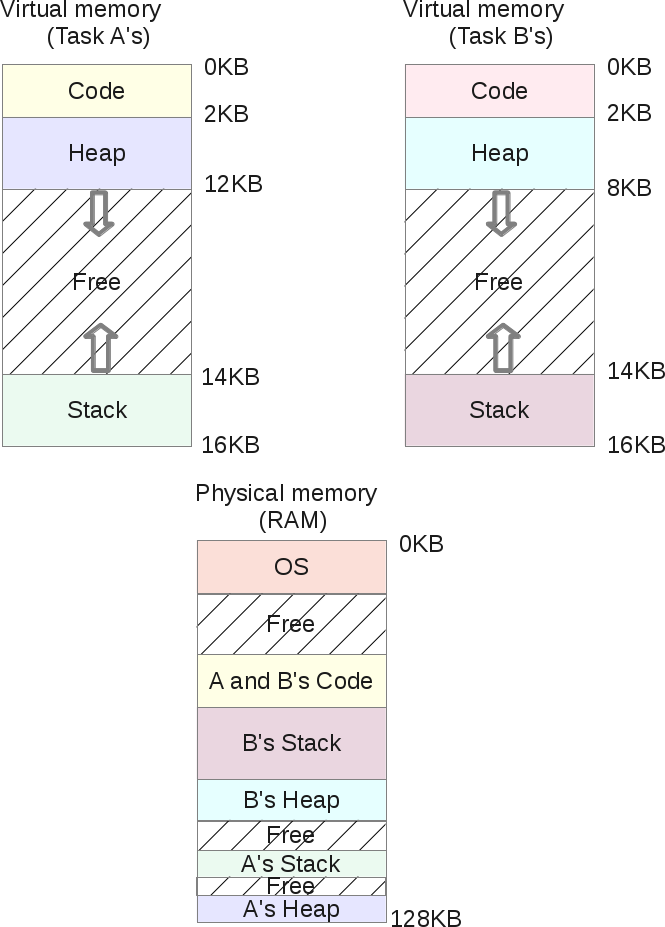
在上图中任务A和任务B在虚拟地址空间中都有各自的代码段,但是它们的代码段会被映射到同一块物理内存的代码段,当然任务A和任务B是意识不到这一点的,在它们看来,它们都是独享一块物理内存段,从底层操作系统的角度来看,它们可以说是被操作系统给耍了。
为了实现这个目的,操作系统必须提供一个额外的功能:段保护位(segment protection bits)。
在每个物理段被创建出来时,操作系统除了会为MMU注册每个段的bounds/limit(界限)外,它还会注册一个权限标志(permission flag)。
如果代码是不能修改的(通常都是这样),代码段的权限标志会被设置为RX(可读可执行)。进程可以加载这个内存区域的指令到CPU中供CPU执行(eXecution),但是如果有任何进程尝试向这个内存区域写入数据的话,操作系统会喝止这个行为。另外两个段,heap和stack都是RW(可读可写),进程可以从它们自己的stack/heap中读取数据,还可以把数据写入其中,但是它们不能执行其中的代码(这种做法可以防止一些应用程序的安全缺陷,恶意用户可能想通过向stack或heap中注入代码来破坏程序的stack或heap,从而获取root权限:如果heap段和stack段是不可执行的话,那么这种情况是不会发生的。但是历史并非一直都是如此,因为这个特性也需要一些硬件的支持,在Intel系列的CPU中这些硬件被称为“NX bit”)。
内存段的权限可以在运行时进行改变:任务可以调用操作系统提供的接口来实现,例如调用mprotect()。
在Linux中,我们可以随时查看某个进程的内存段,可以直接查看/proc/{pid}/maps的内容,或者是使用/usr/bin/pmap这个工具来查看。
下面是一个PHP进程的示例:
$ pmap -x 31329
0000000000400000 10300 2004 0 r-x-- php
000000000100e000 832 460 76 rw--- php
00000000010de000 148 72 72 rw--- [ anon ]
000000000197a000 2784 2696 2696 rw--- [ anon ]
00007ff772bc4000 12 12 0 r-x-- libuuid.so.0.0.0
00007ff772bc7000 1020 0 0 ----- libuuid.so.0.0.0
00007ff772cc6000 4 4 4 rw--- libuuid.so.0.0.0
... ...
上面输出的是PHP这个进程的内存映射的详细信息。第一列是对应的虚拟地址,倒数第二列给出了每个内存区域的权限。我们可以看到,每个共享对象(shared object, .so文件)会被映射到多个段(例如代码段和数据段),代码段是可执行的,任何其他用到同样的共享对象的进程都会将这些共享对象的物理内存映射到各自的地址空间中。
Linux(类Unix系统)中的共享对象的一个最大的有点就是:节省内存。(译注:共享对象也被叫做共享库,它还有一个名字叫做动态链接库,在windows中就是dll文件,有兴趣的同学可以自行搜索动态链接和动态链接库方面的知识)
在Linux中也可以使用mmap()系统调用来创建一个共享区域,这个区域会被映射到一块共享的物理内存段中。
分段的限制(Segmentation limits)
我们已经通过分段解决了无用的虚拟内存空间(unused virtual memory space)造成物理内存浪费的问题。当虚拟内存空间中的某些区域没有被进程使用时,这些区域不会被映射到任何物理内存,每个段对应的都是已使用的内存。
然而这样并非就完美了。
如果一个进程从heap中请求16Kb的内存,这个怎么搞呢?操作系统可以在物理内存中创建一个16Kb大小的段。假设此时用户释放了其中2Kb的内存,这又会发生什么呢?操作系统也许必须得压缩16Kb的段,缩小到14Kb。如果此时程序再突然请求30Kb的heap内存,这又该怎么处理呢?可以把之前的14Kb的段增长到30Kb,这可以做到么?此时可能有一些其他的段环绕着之前的14Kb的段,从而没法增加之前的段。此时操作系统必须得找一个拥有30Kb空闲空间的内存,然后再把之前的14Kb的段重定位到这个区域。
分段的最大问题是会带来很多碎片化的物理内存,这是因为用户级任务会不断要求分配和释放内存,所以这些段需要不断增长和收缩。这样操作系统必须维护一份空闲内存的列表,并对它们进行管理。
这就存在一种情况,操作系统所维护的空闲内存的总和大于进程请求分配的内存,但是这些空闲内存并非连续的,此时操作系统不能把这些空闲空间分配给进程,它只能拒绝进程的内存分配请求,即使此时的空闲物理内存总量大于进程请求的内存的数量。这不是个好现象。
此时操作系统只能对内存进行压缩,把所有的空闲区域合并为一个大的连续的内存块,这样就可以满足之后的分配请求了。
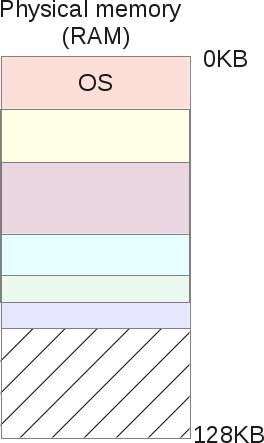
但这个压缩过程非常耗CPU时间,并且在压缩过程中其他的用户进程不能获取CPU时间片:因为此时操作系统正在把所有精力投入到重新组织物理内存的工作中,所以此时系统将变得不可用了。
内存分段可以解决因多任务所引起的很多内存管理方面的问题,但是它仍然有一些缺陷。因此我们需要一些其他的手段来加强分段的能力并解决这些缺陷——这就引出了另外一个概念:内存分页(memory paging)。
内存分页(Memory pagination)
内存分页跟分段有一些共通之处,同时它可以解决分段的一些问题。上面我们已经看到内存分段的主要问题是随着进程请求和释放内存,段会不断增长和收缩。有些时候,操作系统会面对一个问题,它不能找到一块足够大的空闲空间来满足一个用户进程的内存分配请求,这是由于物理内存中存在太多的碎片:物理内存中有很多不同尺寸的段,它们分布在物理内存的不同地方,这会导致物理内存高度的碎片化。
分页使用了一个简单的概念来解决这个问题:如果内核(the Kernel)对每个分配请求分配固定尺寸的内存呢?页就是固定尺寸的物理内存段,仅此而已。如果操作系统分配固定尺寸的物理内存,那么它就能更好地管理这些空间,从而可以消除物理内存的碎片。
我们来看一个示例,我们还是以16Kb的虚拟地址空间为例:
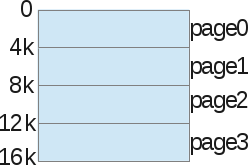
为了讲解分页,我们先不考虑heap、stack和code这几个内存段,我们会把整个进程的虚拟地址空间分配为几个大小固定的区域:我们把它们称为页。在这个示例中,我们把地址空间分为4个页,每页的大小为4Kb。
此外我们也会对物理内存进行同样的分页处理。
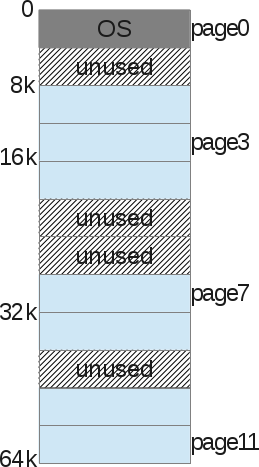
操作系统把这些分页信息保存在一个名为“进程页表(process page table)”的结构中,页表保存了一个进程的虚拟内存页跟所使用的物理内存页的对应关系(这也被称为“页帧(page frame)”)。
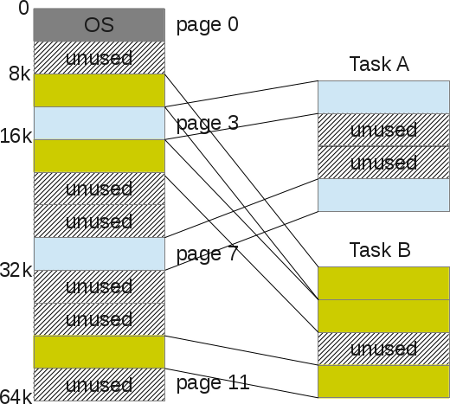
使用这种方式管理内存不会带来空闲空间管理的问题:每个页帧要么已被映射(mapped,这表示已经被使用),要么没有被映射;这样内核也会很方便地找到足够的页来满足用户进程的内存请求,它只需要简单地维护一个页帧的空闲列表,然后在每次内存分配请求时浏览这个列表。
页是操作系统可管理的最小内存单元。一个页是不可再分的(至少在操作系统分配内存这个层面上)(译注:这里的内存分配是指操作系统为进程分配的内存,这个必须是以页为单位,也就是说假设你的程序只有1Kb,而每个页最小是4Kb,那么你必须分配一页(4Kb)的物理内存给这个程序,剩下的其实也是碎片,这种碎片叫做内部碎片,而这种碎片是不能进行转移和合并的,还有另外一种内存分配——用户进程在运行过程中从heap中请求的内存,这种内存分配叫做动态内存分配,也就是在C程序中使用malloc函数分配的内存,这个内存分配的大小可以是任意,小到几个字节,大到几G都可能,只要虚拟地址空间的heap段足够大,并且有足够的物理内存,在C程序中这个内存的分配是由C的运行库管理的)。
当使用了分页后,每个进程都会关联一个页表结构,它们会保存所有的地址转换。地址转换不需要再使用bounds/limit了,而是使用一个“虚拟页号(VPN,virtual page number)”和一个页中“偏移(offset)”。
我们再来看一个使用分页后的地址转换的示例。我们还是假设虚拟地址空间的大小为16Kb,此时我们需要14位来表示一个地址(2^14 = 16Kb)。页的大小为4Kb,所以我们需要4Kb(16/4)来选择我们的页(译注:这个4Kb说的是页内偏移,偏移(offset)最大为4Kb):

现在,我们假设要加载虚拟地址9438的物理内存,这个地址的二进制表示为10.0100.1101.1110,如下图所示:

这个地址表示页号为2的虚拟页的第1246个字节开始的数据("0100.1101.1110”表示第1246个字节的偏移,“10”表示页号为2)。现在操作系统只需要在这个进程的页表中查找页号为2的虚拟页所映射的物理页。根据之前的设定,页号为2的虚拟页被映射到以8K为起始地址的物理页,所以虚拟地址9438对应的物理地址是9442(8k+1246的偏移)。这样就找到了我们想要的数据。(译注:在上面我没有看到页表的设定,而且从上面的图中也看不出这个2号虚拟页会被映射到8K处的物理内存,至少看来很勉强,但是我想他说描述的意思还是很好理解的)。
正如我所说的,每个进程都有一个页表,这是因为每个进程有各自独立的地址转换,这跟段类似。但是显然我们会有一个疑问:这些页面会存储在什么地方?猜猜看。。。当然是在物理内存中啊,不然还会在哪里呢?
如果页表被保存在内存中,这就意味着每次内存访问都需要先从内存中取出VPN对应的物理内存页的地址,然后再根据偏移计算出真正要访问的物理地址,最后再访问这个物理地址取得对应的数据,这就意味着每次内存访问的请求都会产生两次内存访问的行为:一次是获取页表,另一次是访问“真正”的数据。对于CPU而言,内存访问是很慢的操作,那么把页表放在内存中似乎并非一个好的解决方案?
TLB:快速重编址缓冲器(Translation-lookaside Buffer : TLB)
使用分页作为核心机制来实现虚拟内存的分配和到物理内存的映射会导致更高的性能开销。通过把地址空间划分为一些更小的大小固定的单元(页),为了实现分页需要记录很多映射信息。由于这些映射信息通常都被保存在物理内存中,所以分页逻辑需要一次额外的内存访问,才能根据程序的虚拟地址找到对应的数据。
前面说过,对于CPU而言内存访问的开销还是很大的(译注:大概几百个时钟周期吧,大概是访问寄存器的100倍),所以为了加快这个过程,我们需要引入新的硬件来协助操作系统,就像我们之前在分段里面引入MMU一样,这个硬件将协助操作系统内核以一种更高效的方式实现地址转换。TLB是MMU的一部分,并且它只是一个用于VPN转换的缓存。TLB会缓存一部分虚拟页到物理页的映射,从而可以减缓将虚拟地址转换为物理地址的内存访问次数。(译注:这实际上是一种缓存技术,MMU位于CPU芯片中,访问MMU的速度跟访问寄存器的速度差不多,另外利用程序的局部性原理,这种技术可以极大的提升转换虚拟地址的速度,当然因为这只是一种缓存技术,所以必然存在缓存不命中的情况,这个时候还是需要两次访问内存的)
在每次虚拟内存访问时都会使用MMU,它会先从地址中提取出VPN,然后根据这个VPN查找TLB中是否有对应的VPN。如果命中(hit),它会直接返回TLB中记录的对应的物理地址,完成它的使命。如果没有命中(miss),那么它会查找进程的页表,如果对这个物理地址的访问是合法的,那么它会更新TLB,那么之后再访问这个虚拟地址,就会命中了。
跟其他的缓存机制一样,命中要优于未命中,因为在不命中的情况下会触发页表查询,从而增加一次额外的内存访问。既然如此,你也许会认为每个内存页的大小越大,也许会越有利于TLB命中的情况,但这也可能会造成每个内存页中更多的空间浪费,我们需要根据实际的情况找到一个平衡点。现代操作系统内核支持使用不同的内存页尺寸,例如Linux内核支持一种称为“巨页(huge page)”的内存页尺寸,这个尺寸可以达到2Mb,而不是传统的4Kb的内存页。
另外,你最好把信息保存在连续的内存区域中。如果你把数据分散放到内存中,你可能会遭受大量的TLB未命中情况,或者是TLB缓存用完的情况。这就是局部性原理的作用:应用程序倾向于立即访问同一个物理页中的数据,这就会产生大量的TLB命中,从而使当前的内存访问更高效。
对于上下文切换,TLB会在每个条目(entry)上存储一个名为ASID的字段。ASID指的是地址空间标识符(Address Space Identifier),如同进程的PID。每个被调度的进程都会有自己的ASID,这样TLB就可以区分每个进程的地址空间,从而不会出现把进程的虚拟地址转换成了其他进程的物理地址的情况。
如果用户进程想加载一个无效的地址,那么这个地址不可能出现在TLB中,此时会产生一个未命中,然后会查找进程的页表。这个地址会存在于页表中(每个可能的地址转换都会被保存在页表中),但是它会被设置为无效的标志位(译注:这里的说法其实并不完全正确,无效地址有多种情况,首先明确一下这个无效地址说的是虚拟地址,所以如果这个地址的大小超过了最大的虚拟地址,或者是访问属于操作系统内核的虚拟地址,此时都不会查找页表而直接报错,除此之外的地址确实都可以通过查找页表找到对应的物理地址,而操作系统只有根据页表项中保存的权限字段来判断这个地址访问是否有效,例如对代码段进行写操作就是一个无效的操作,但这并不是说地址是无效,这是一个综合的过程,而不能简单地说某个地址是无效的,确切地说是对这个地址的操作是无效的)。在X86中,每个保存地址转换的页表条目都会使用4个字节保存相关信息,这4个字节中有些位是标识这个地址是否有效的位(valid bit),有些位是内存页是否发生改变的标志(dirty bit),有些位是用于内存保护的权限标志(protection bit),有些位也会用于表示引用(reference bit)等等。如果某个条目被表示为无效,那么对这个地址的访问就会产生一个SIGSEGV信号,这就是所谓的“段错误(segmentation fault)”,到此为止我们就不会再讨论段了。
你需要知道在现代操作系统中分页是一个比我这篇文章中介绍的情况要复杂得多的技术。现代操作系统都使用了多级页表,多种页尺寸,另外还有一个重要的概念我没有谈论:页驱逐(page eviction),也被称为“换页(swapping)”内核在内存和磁盘之间交换页数据,这可以更有效地使用主存,从而给用户进程一种拥有无限主存的幻觉)(译注:我们多数时候理解的换页就是在物理内存不够用的时候,把内存中的某些数据放到磁盘上,但是因为进程所看到的只是虚拟地址空间,所以它不会知道它所访问的虚拟地址对应的数据是在主存上,还是在磁盘上,另外换页发生的时候,只会把当前正在睡眠的进程(或者是优先级更低的进程)所占用的内存交换到磁盘上,再把空出来的内存分配给正在运行中的需要内存的进程,所以并不是空间不足,就给正在运行中进程分配一些磁盘空间来弥补内存的不足)
(译注:另外还有一个常见的误解,有时候我们会把用于换页的交换分区当作是虚拟内存,这么理解虚拟内存的人都只是把虚拟内存看成了是内存的扩充,这实际上完全搞错了虚拟内存的含义,虚拟内存可以说是计算机历史上最伟大的技术创新之一,相信你通过这篇文章也可以体会到它的精妙之处)
总结
现在你应该大概明白了“段错误(segmentation fault)”的消息所表示的含义了。操作系统曾经使用段来表示虚拟内存空间到物理内存空间的映射。当一个用户级进程想访问一些内存,它会产生一个访问请求,MMU会把请求的虚拟地址转换为对应的物理内存地址。但是如果这个地址访问存在错误:转换后的物理地址超出了物理段的界限,或者违反了段保护权限(例如请求向只读段中写入数据),此时默认情况下操作系统会产生一个表示需要进行错误处理的信号:SIGSEGV,对这个信号的默认处理行为(default handler)是杀死(kill)这个进程,并且输出一个消息:“Segmentation fault”。在一些其他的操作系统(猜猜是什么操作系统)中,错误消息会是“General protection fault”。Linux操作系统是开源的,所以我们可以查看它的源代码,从这里可以看到管理内存访问的错误(X86/64平台):http://lxr.free-electrons.com/source/arch/x86/mm/fault.c , 另外在此可以看到关于SIGSEGV的代码。
如果你对X86/64平台上的段的设计有兴趣,你可以看看Linux内核中对它们的定义。在此你还可以看到一些关于内存分页的有趣的东西,内存分页比起传统的段的使用更进一步推进了内存分段的概念。
我很喜欢写这种文章,它让我有一种回到了90年代末的感觉。那个时候我在为我的第一个CPU编程:Motorola 68HC11,使用C、VHDL和汇编。我没有设计一个拥有虚拟内存管理的操作系统,而是直接访问物理地址(这种CPU不需要这么复杂的机制)。后来我转向了Web开发;我最开始的技术知识都源于电子学,每天都使用我们自己造的系统。。。牛逼吧:)