深入理解Zend执行引擎(PHP5)
这是Julien Pauli的另外一篇文章,算上这篇我已经翻译了三篇他的文章了,他的文章基本上都是关于PHP底层的,在国内很少有人能写出这么详细的关于PHP底层的内容,即使是在国外也很少,接下来我还会再翻译几篇他的文章。关于Zend引擎我就不说什么,这篇文章已经说得很清楚了,好好享受吧!PHP:一种解释型语言
PHP经常会被定义为“脚本语言”或者是“解释型语言”,什么是“解释型语言”呢?
所谓“解释型语言”就是指用这种语言写的程序不会被直接编译为本地机器语言(native machine language),而是会被编译为一种中间形式(代码),很显然这种中间形式不可能直接在CPU上执行(因为CPU只能执行本地机器指令),但是这种中间形式可以在使用本地机器指令(如今大多是使用C语言)编写的软件上执行。
这个软件就是所谓的软件虚拟机(software virtual machine)。我们先看下Wikipedia上对软件虚拟机的定义:
(…)进程虚拟机(process virtual machine)通过提供一个抽象的平台独立的程序执行环境来执行某种计算机程序。进程VM(译注:VM是virtual machine的缩写)有时候也被称为应用程序虚拟机,或者是可管理运行环境(Manged Runtime Environment,简称MRE),它会以一个普通应用的形式运行在宿主操作系统中(host OS),在运行中,他是宿主操作系统中一个单独的进程。在这个进程启动时,VM会被创建,退出时则会被销毁。它的目的是提供一种平台独立的程序执行环境,它可以对底层硬件或操作系统进行抽象处理,从而保证应用程序可以在任何平台上以一致的行为执行。
跟任何解释型语言一样,PHP语言也被设计为一种可以跨平台执行抽象指令的程序,尽可能地抽离掉底层操作系统的细节。这是技术上的解释。在功能应用上,PHP的主要领域是Web应用(PHP的目的是解决Web应用的相关问题)。
当前市面上还有其他一些基于软件虚拟机的语言(不完全列表):Java、Python、C#、Ruby、Pascal、Lua、Perl、Javascript等等。基本上使用这些语言编写的程序都不会被直接编译为本地机器指令,这些程序都是运行在一个软件虚拟机上。为了性能考虑,有些软件虚拟机可以把部分(并非全部)语言的中间代码直接转换为机器指令来执行:这个过程被称为“JIT编译”。在我写这篇文章时PHP并未使用JIT编译技术,不过有些实验性的工作正在进行,PHP社区也经常会提及和探讨这个话题。(译注:这篇文章写于15年2月份,此时HHVM应该已经发布,而HHVM就使用了JIT,另外最新版的PHP7貌似也使用了JIT)
软件虚拟机之所以如此流行,主要是因为我们不想为了在屏幕上输出一个“Hello”而写几千行的C代码(译注:这个有点夸张了吧,不过考虑到平台相关性,使用C写程序确实要考虑更多,至少是需要在不同的机器上编译所写的程序,但为了输出一个“hello”写几千行的代码就太夸张了,因为输出“hello”的主要工作都是由C运行库提供的函数完成的,尽管不同平台运行库的代码肯定有差别,但接口还是基本上完全一致的)。使用软件虚拟机相对于基于本地平台的程序开发有如下优点:
- 使用简单,便于开发
- 基本上都支持自动内存管理
- 支持抽象目标数据类型,没必要进行底层的数学运算(译注:这个应该指的是地址运算,这个在C中和汇编编程中都非常常见),没必要因为切换目标硬件平台而重新编写代码
当然也有些不足之处:
- 不可能精确地管理内存或全局资源的使用(唯有信任VM)
- 执行速度无法比拟本地机器代码:完成相同的任务需要更多的CPU周期(JIT就是用于减小这个差距的,但不可能消除)
- 可能会抽象很多东西,通常程序员会远离硬件,从而无法全面理解代码的确切影响,特别是在负载过大的情况下
最后一条就是我写这篇文章的目的。随着时间的推移,我越来越注意到一个事实:越来越少的程序员能够确切地掌握他们所写的代码对硬件和网络的影响,在我个人看来这并非是什么好现象。这就像某个人把两根电线连在一起,然后双手合十祈祷整个系统不要挂掉。当然我的意思并不是希望大家能够掌握整个链条上的所有东西,这不是人力可为的,我只是希望大家至少清楚我们所谈论的这些东西的深层含义。
所以我会尽力向你展示PHP对你所写的代码做了什么。当你掌握了这些知识后,你可以从举一反三,把这些知识应用到任何其他“解释型”语言上,因为它们在设计上跟PHP的差别不大,它们有很多共通的概念。通常而言,你在学习其他的解释型语言的过程中,你会发现它们之间的主要区别只是是否使用了JIT,或者是否可以并行执行(主要是使用线程,PHP没有提供任何并行技术),其他的差别可能就是内存池(memory pooling)和垃圾回收算法上的不同了。
Zend软件虚拟机
PHP使用主要虚拟机(Zend虚拟机,译注:HHVM也是一种执行PHP代码的虚拟机,但很显然Zend虚拟机还是目前的主流)可以分为两大部分,它们是紧密相连的:
- 编译栈(compile stack):识别PHP语言指令,把它们转换为中间形式
- 执行栈(execution stack):获取中间形式的代码指令并在引擎上执行,引擎是用C或者汇编编写成的
这篇文章不会谈论第一部分,而会专注于Zend虚拟机的executor(译注:executor可以翻译为执行器,但似乎鲜有这种说法,所以后面直接使用这个英文单词,而不作翻译),executor是一个很意思的软件,它具有高度优化、跨平台、运行时hookable(译注:这个词不好翻译,大概意思就是可以通过设置某种钩子获取运行时信息,像VLD这种扩展就是这么实现的)等优点,在技术上非常有挑战性。它包含几千行C代码,每次新发布的PHP版本都会对它做部分重写。
我们在这篇文章中以PHP5.6为例来讲解。
首先我必须得承认关于这个话题有太多可讨论的东西,以至于我不知道从哪里开始,也不知道该给大家展示哪些知识,以怎样的顺序来展示。这种情况在我写之前的文章时并不常见,但我也不打算把这个话题分成几篇文章来讲述,因为所有这些部分都是紧密相连的。另外需要提醒大家的时在没有编译器相关知识的前提下,也可以非常好地理解executor,尽管它们俩是紧密相连的;当我把巨大的executor分解为多个部分逐渐呈现在你眼前后,你就可以理解它的每一个概念。当然,完全理解executor并非易事,需要一些时间。
所以也希望你能够意识到,如果你不了解PHP编译器是怎么工作的,这不会影响你学习和理解executor。也许以后我会再写一篇PHP编译器方面的文章。
好了,我们开始吧。
OPCode
如果你了解PHP内部机制方面的知识,或者是看过我之前的Blog,你也许已经很多次见到过这个词。我们还是先看下Wikipedia上的解释:
OPCode也会出现在所谓的字节码(byte codes)中,或者是被软件解释器(而不是硬件设备)解释执行的指令的其他形式中。这些软件指令集通常会提供一些比对应的硬件指令集更高级(higher-level)的数据类型和操作,尽管它们每个指令执行的结果都是差不多的。
ByteCode和OPCode其实是两个含义不同的词,但我们经常会把它们当作同一个意思来交互使用。
我们假设Zend VM的一个OPCode对应虚拟机的一个底层操作。Zend虚拟机有很多OPCode:它们可以做很多事情。随着PHP的发展,也引入了越来越多的OPCode,这都是源于PHP可以做越来越多的事情。你可以在PHP的源代码文件Zend/zend_vm_opcodes.h中看到所有的OPCode。
通常而言,OPCode的名称是自描述的,例如:
- ZEND_ADD :执行两个操作数的算术加法运算
- ZEND_NEW :创建一个对象(一个PHP对象)
- ZEND_EXIT :退出PHP执行
- ZEND_FETCH_DIM_W : 取一个操作数在某个维度(dimension)下的值,然后执行写入操作(译注:这里的“维度”指的一维数组,二维数组的“维度”,给数组中的某个元素赋值,或者是给字符串所在某个位置的字符赋值都会用到这个OPCode)
- 等等
PHP5.6有167个OPCode。因此我们可以说PHP5.6的虚拟机的executor可以执行167种不同的(计算)操作。
PHP内部使用zend_op这个结构体来表示OPCode:
struct _zend_op {
opcode_handler_t handler; /* The true C function to run */
znode_op op1; /* operand 1 */
znode_op op2; /* operand 2 */
znode_op result; /* result */
ulong extended_value; /* additionnal little piece of information */
uint lineno;
zend_uchar opcode; /* opcode number */
zend_uchar op1_type; /* operand 1 type */
zend_uchar op2_type; /* operand 2 type */
zend_uchar result_type; /* result type */
};你可以通过设想一个简单的计算器来理解OPCode(严肃点,我说真的):这个计算器可以接收两个操作数(op1和op2),你请求它执行一个操作(handler),然后它返回一个结果(result)给你,如果算术运算出现了溢出则会把溢出的部分舍弃掉(extended_value)。
OPCode就是些东西,不需要添加任何其他的东西,它的概念很容易理解。
Zend VM的每个OPCode的工作方式都完全相同:它们都有一个handler(译注:在Zend VM中,handler是一个函数指针,它指向OPCode对应的处理函数的地址,这个处理函数就是用于实现OPCode具体操作的,为了简洁起见,这个单词不做翻译),这是一个C函数,这个函数就包含了执行这个OPCode时会运行的代码(例如“add”,它就会执行一个基本的加法运算)。每个handler都可以使用0、1或者2个操作数:op1和op2,这个函数运行后,它会后返回一个结果,有时也会返回一段信息(extended_value)。
我们先来看看ZEND_ADD这个OPCode的handler:
ZEND_VM_HANDLER(1, ZEND_ADD, CONST|TMP|VAR|CV, CONST|TMP|VAR|CV)
{
USE_OPLINE
zend_free_op free_op1, free_op2;
SAVE_OPLINE();
fast_add_function(&EX_T(opline->result.var).tmp_var,
GET_OP1_ZVAL_PTR(BP_VAR_R),
GET_OP2_ZVAL_PTR(BP_VAR_R) TSRMLS_CC);
FREE_OP1();
FREE_OP2();
CHECK_EXCEPTION();
ZEND_VM_NEXT_OPCODE();
}
你只需要注意其中你可以理解的行,上面的这段代码并不符合C语法(这一点等会会谈到)。尽管如此,这段代码还是很容易理解的。
正如前面所说,ZEND_ADD这个OPCode的handler中会调用fast_add_function()函数(一个存放在其他地方的C函数),这段代码中给这个函数传入了三个参数:result(结果)、op1和op2。从这段代码我们可以看出真正执行加法运算的代码是在fast_add_function()这个函数中,在此我们就不展示这个函数的代码了。
上面的handler代码的最后部分会调用CHECK_EXCEPTION()和ZEND_VM_NEXT_OPCODE()两个指令(译注:实际上是两个C的宏),我们先讲解一下后一个指令(instruction)。
一个超大的循环(A giant loop)
当在编译PHP脚本时,脚本中的PHP语法会被转换为多个OPCode,一个接着一个。这是编译器的工作,在此不详述。
这意味着PHP编译器会做一件事情:把PHP脚本转换为一个“OP数组(OP array)”,它是一个包含多个OPCode的数组。每个OPCode的handler都会以调用ZEND_VM_NEXT_OPCODE()结束,它会告诉executor提取(fetch)紧接着的下一个OPCode,然后执行它,这个过程会不断进行。
所有这些都发生在一个循环里,它的代码如下(经过简化后的代码)(译注:实际上这个while循环体中的代码也不复杂,而execute_ex整个函数也不大,作者说是一个超大的循环,他想表达的意思应该是这个循环的执行时间,因为基本上所有的OPCode的执行都是通过循环发起的,你可以通过这个链接查看这个函数的代码):
ZEND_API void execute_ex(zend_execute_data *execute_data TSRMLS_DC)
{
zend_bool original_in_execution;
original_in_execution = EG(in_execution);
EG(in_execution) = 1;
zend_vm_enter:
execute_data = i_create_execute_data_from_op_array(EG(active_op_array), 1 TSRMLS_CC);
while (1) { /* infinite dispatch loop */
int ret;
if ((ret = execute_data->opline->handler(execute_data TSRMLS_CC)) > 0) { /* do the job */
switch (ret) {
case 1:
EG(in_execution) = original_in_execution;
return; /* exit from the infinite loop */
case 2:
goto zend_vm_enter;
break;
case 3:
execute_data = EG(current_execute_data);
break;
default:
break;
}
}
} /* end of infinite dispatch loop */
zend_error_noreturn(E_ERROR, "Arrived at end of main loop which shouldn't happen");
}
上面代码中的循环被称为的Zend executor的主分发循环(dispatch loop)。一个while(true)的死循环,它会执行一个handler函数,这个函数以ZEND_VM_NEXT_OPCODE()这个指令结束,这个指令会告诉executor把execute_data->opline指向到OPArray中的下一个OPCode。
#define ZEND_VM_NEXT_OPCODE() \
CHECK_SYMBOL_TABLES() \
ZEND_VM_INC_OPCODE(); \
ZEND_VM_CONTINUE()
#define ZEND_VM_INC_OPCODE() \
OPLINE++
#define OPLINE execute_data->opline
#define ZEND_VM_CONTINUE() return 0
#define ZEND_VM_RETURN() return 1
#define ZEND_VM_ENTER() return 2
#define ZEND_VM_LEAVE() return 3
我们可以把整个执行场景简化为:“执行操作1,执行操作2,执行操作3,…,返回退出(return and exit)”。等会再探讨这个循环是怎么实现的,目前只需要把它理解为执行一系列操作就可以。
(译注:这里有必要说明一下,实际上并非所有的handler最后都会调用ZEND_VM_NEXT_OPCODE()这个宏,例如ZEND_GENERATOR_RETURN这个OPCode的handler最后调用的就是ZEND_VM_RETURN()这个宏,它会返回1,这种情况下会退出循环,我们通过上面的宏的定义也可以看出,所有调用ZEND_VM_NEXT_OPCODE()这个宏的handler都会ZEND_VM_CONTINUE()这个宏返回0,这种情况下会进入下一次循环,也就是执行下一个OPCode)
一个简单的示例
我们先看一个简单的示例:
$a = 8;
$b = 'foo';
echo $a + $b;
这个简单的脚本会被编译成如下所示的OPArray(由ext/vld扩展生成)。
compiled vars: !0 = $a, !1 = $b
line #* I O op fetch ext return operands
-----------------------------------------------------------------------------------
2 0 > ASSIGN !0, 8
3 1 ASSIGN !1, 'foo'
4 2 ADD ~2 !0, !1
3 ECHO ~2
5 4 > RETURN 1
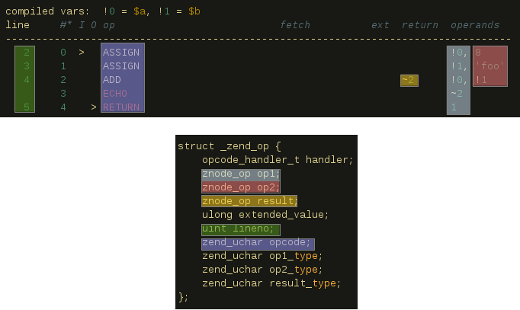
相信大家可以理解上面输出的OPCode,我在此简单说明下:
- 把8赋值(assign)给$a
- 把'foo'赋值给$b
- 把$a和$b中的值相加然后保存在一个临时变量“~2”中
- echo临时变量“~2”
- 返回(return)
你可能已经注意到一个最后一行的OPCode:RETURN,这个OPCode出现在这里似乎有点奇怪。它是干嘛的呢?它是从哪里来的呢?这个问题实际上很简单。
还记得上面那个超大的while()循环么?它是一个无限循环:while(1),再回去分析一下这个简单的循环,你会注意到结束这个循环的唯一方式是handler()函数执行后返回1,它会将while中的代码导向switch的case 1分支,这个分支中有一个return语句,它会导致循环退出。RETURN这个OPCode不做任何事情, 除了返回1,终止Zend VM Executor的分发循环(dispatch loop),然后返回。所以很显然:每个脚本都会以一个RETURN结束,如果不是这样的话:整个循环会无限执行下去,这显然是不合理的。
所以PHP编译器被设计为不管编译什么代码都会在编译出的OP数组的最后加一个RETURN的OPCode。这意味着如果编译一个空的PHP脚本(不包含任何代码),所产生的OPArray中也会包含一个唯一的OPCode:ZEND_RETURN。当它被加载到VM的执行分发循环时,它会执行这个OPCode的handler的代码,那就是让VM返回:空PHP脚本不会做其他任何事情。
OPArray
我们已经多次使用到“OPArray”这个词了,现在来看看它的定义。之前使用这个词时,我建议把它简单地理解成一个包含顺序执行的OPCode的数组。就像下图所示的样子:
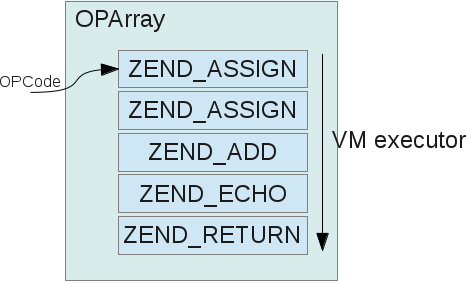
然而这种说法并不完全正确,尽管它离真实情况也差得不远。下面是表示OPArray的结构体:
struct _zend_op_array {
/* Common elements */
zend_uchar type;
const char *function_name;
zend_class_entry *scope;
zend_uint fn_flags;
union _zend_function *prototype;
zend_uint num_args;
zend_uint required_num_args;
zend_arg_info *arg_info;
/* END of common elements */
zend_uint *refcount;
zend_op *opcodes;
zend_uint last;
zend_compiled_variable *vars;
int last_var;
zend_uint T;
zend_uint nested_calls;
zend_uint used_stack;
zend_brk_cont_element *brk_cont_array;
int last_brk_cont;
zend_try_catch_element *try_catch_array;
int last_try_catch;
zend_bool has_finally_block;
HashTable *static_variables;
zend_uint this_var;
const char *filename;
zend_uint line_start;
zend_uint line_end;
const char *doc_comment;
zend_uint doc_comment_len;
zend_uint early_binding;
zend_literal *literals;
int last_literal;
void **run_time_cache;
int last_cache_slot;
void *reserved[ZEND_MAX_RESERVED_RESOURCES];
};如你所见,这个结构体所包含的东西绝不仅仅只有一个包含OPCode的数组。包含OPCode的数组只是这个结构体中的一个字段:
struct _zend_op_array {
/* ... */
zend_op *opcodes; /* Here is the array of OPCodes */
/* ... */
}记住当引擎编译PHP脚本时,编译器会返回一个上面所示的OPArray,这是它的唯一工作。
所以一个“OPArray”不是我们通常所理解的一个包含zend_op(OPCodes)元素的C数组,实际上它还包含一些统计信息,以及所有有利于OPCode以最高效的方式执行所需的信息:executor必须得尽可能高效地执行OPCode,唯有如此,PHP脚本的运行才可能花费尽可能少的时间。
下面详细说明下OPArray中包含的一些信息(只讲最重要的几个):
- 当前脚本的文件名(const char *filename),以及会被编译为OPArray的PHP脚本在文件中的开始行数(zend_uint line_start)和结束行数(zend_uint line_end)
- 文档注释的信息(const char *doc_comment):PHP脚本中使用“/**”注释的信息
- 引用计数(zend_uint *refcount),OPArray本身也可能会在其他地方共享,所以需要记录它的引用情况
- 编译变量列表(zend_compiled_variable *vars)。编译变量(compiled variable)是所有PHP脚本中使用的变量(以$something的形式出现)
- 临时变量列表:临时变量用于保存运算的临时结果,这些结果不会显示地在PHP脚本中使用(不是使用$something的形式在PHP脚本中出现,但是是会被真正用到的中间数据)(译注:从上面的结构体中我看不出哪个是保存临时变量的字段)
- try-catch-finally的信息(zend_try_catch_element *try_catch_array),executor需要这些信息来实现正确的跳转
- break-continue的信息(zend_brk_cont_element *brk_cont_array),executor需要这些信息来实现正确的跳转
- 静态变量的列表(HashTable *static_variables)。静态变量会被特殊处理,因为它们的信息需要维持到PHP生命周期的最后时刻(大体上是这样)
- 字面量(zend_literal *literals)。字面量是指任何在编译期就知道它的值的东西(译注:实际上就是常量),例如我们在代码中使用的字符串'foo',或者是整型42
- 运行时缓存槽(cache slot):这个地方用于缓存引擎执行过程中还用会用到的东西
OK,看起来似乎这个结构体中被塞进了很多东西?
还有件重要的事情我没有提到:OPArray结构体会在编译脚本、PHP用户自定义的函数和所有传入evel()函数的字符串这几个PHP语言结构时使用。当你编写一个PHP函数,它的整个函数体会被编译为一个单独的OPArray,这个OPArray会包含在函数体中使用的编译变量(compiled variable),在函数体中使用的try-catch-finally语句等等。(译注:这段话的意思是说明哪些PHP代码会被编译为OPArray这个结构体,PHP编译器并不是只编译出一个OPArray,而且也不是把任何代码都编译为OPArray,哪些语言结构需要被编译为OPArray是有原则的。对于PHP编译器而言,它会把PHP脚本(就是除开函数和传入eval()的字符串的所有PHP代码都是PHP脚本)、用户自定义函数和传给eval()的字符串这三个东西单独编译为一个OPArray结构体)
OPArray结构体是Zend编译器在编译PHP脚本和PHP用户定义的函数或方法(function/method)后的输出结果。这也为什么你可以从OPArray中读取只跟一个PHP函数相关而跟PHP脚本无关的信息的原因:例如你可以只读取一个函数的文档注释块(documentor comment block)。(译注:实际上我们在使用vld查看OPCode的时候,它输出的OPCode分成几块,每一块就代表一个OPArray,而且通常第一块都是PHP脚本的OPArray,这个总是存在的,你可以自己用vld试试)
Ok,回到前面的示例代码,我们看看它被编译后生成的OPArray是什么样子:
$a = 8;
$b = 'foo';
echo $a + $b;
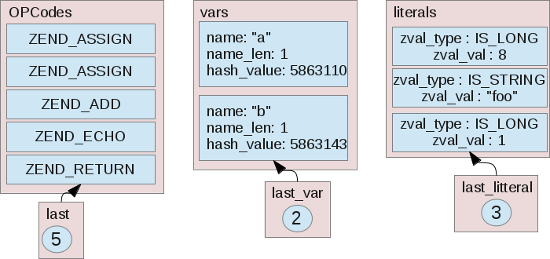
从这些图片中你可以看到这个OPArray现在包含所有需要传给executor的东西。记住一个原则:在编译期(生成OPArray的时候)进行的计算越多,那么executor所要进行的计算就越少(译注:这就是运行期),这样executor就可以专注于它“真正”的工作:执行编译后的PHP代码。我们可以看到所有的字面量都会编译进了literals数组(你可能会注意到literals数组中的整型1,它是来自ZEND_RETURN这个OPCode,它会返回1)。
其他的zend_op_array字段基本都是空的(值为0,译注:指针字段的值会为NULL,NULL也是一种0值),这是因为我们所编译的脚本非常小:里面没有任何函数调用,也没有任何try-catch结构,或者是break-continue语句。这就是编译一段PHP脚本后得到的结果,而不是编译一个PHP函数的结果。在其他情况下会生成不同的OPArray,有些情况下生成的OPArray中的很多字段都会被填充。
Zend VM的操作数类型
在讲解不同的OPCode的handler之前,我们还需要理解另外一个重要概念:操作数。
我们知道每个OPCode的handler最多可以使用两个操作数:op1和op2。每个操作数都表示一个OPCode的“参数(parameter)”。例如,ZEND_ASSIGN这个OPCode的第一个参数是你要赋值的PHP变量,第二个操作数是你要给第一个操作数赋的值。这个OPCode的结果不会用到。(译注:这一点很有意思,赋值语句会返回一个值,这就是我们可以使用$a=$b=1这个语言结构的原因,基本很多语言都是这么做的,但是理论上语句(statement)是不返回值的,例如if语句或者for语句都是不会返回值的,这也是不能把它们赋值给某个变量的原因,在程序设计语言中,能够返回值的都是表达式(expression),有些人吐槽这种设计不合理,因为这违反了一致性原则)
这两个操作数的类型可能不同,这依赖于它们所表示的东西,以及它们是怎么被使用的,我们下面看一下Zend VM所支持的所有操作数类型:
- IS_CV :编译变量(Compiled Variable):这个操作数类型表示一个PHP变量:以$something形式在PHP脚本中出现的变量
- IS_VAR : 供VM内部使用的变量,它可以被其他的OPCode重用,跟$php_variable很像,只是只能供VM内部使用
- IS_TMP_VAR : VM内部使用的变量,但是不能被其他的OPCode重用
- IS_CONST : 表示一个常量,它们都是只读的,它们的值不可改变
- IS_UNUSED :这个表示操作数没有值:这个操作数没有包含任何有意义的东西,可以忽略
ZEND VM的这些类型规范很重要,它们会直接影响整个executor的性能,以及在executor的内存管理中扮演重要的角色。当某个OPCode的handler想读取(fetch/read)保存在某个操作数中的信息时,executor不会执行同样的代码来读取这些信息:而是会针对不同的操作数类型调用不同的(读取)代码。
这是什么意思呢?我们假设某个OPCode的handler要读取的操作数(op1或者op2)的类型是IS_CV,这表示这个操作数是某个在PHP代码中定义过的$variable,这个handler会首先会查找符号表(symbol table),符号表里存放了每个代码中已声明的变量。查找符号表的工作一旦结束,在此我们假设查找是成功的——找到了一个编译变量(Compiled Variable),那么跟当前执行的OPCode处在同一个OPArray中的OPCode(位于当前OPCode后面)非常非常有可能会再次用到这个操作数的信息。所以当第一次读取成功后,executor会把读取的信息缓存在OPArray中,这样之后要再次读取这个操作数的信息时就快很多。
上面是对IS_CV这个类型的解释说明,这也同样适用于其他的类型:我们可以对任意OPCode的handler的操作数访问进行优化,只要我们知道它们的类型信息(这个操作数可共享么?它需要被释放么?之后还可能重用它么?等等)。
从下面这个简单的加法示例中你可以看到PHP编译器是怎么使用每个类型的:
$a + $b; // IS_CV + IS_CV
1 + $a; // IS_CONST + IS_CV
foo() + 3 // IS_VAR + IS_CONST
!$a + 3; // IS_TMP + IS_CONST (此处会产生两个OPCode,但只显示了一个)
OPCode的专用handler(specialized handlers)
现在我们知道每个OPCode的handler最多可以接受两个操作数(参数),并且它会根据操作数的类型来获取它们的值。如果每个OPCode的handler代码中都使用switch()语句来选择每个操作数的类型,再根据不同的类型执行不同的读取操作数的值的代码,那么这会导致严重的性能问题,这是由于CPU无法对每个handler中的分支跳转代码进行优化,因为分支跳转在本质上是一种高度动态化的过程。(译注:这种优化跟CPU执行机器码指令的方式相关的,现代CPU都支持流水线技术(pipeline)(当然最新的CPU使用的是乱序执行的方式,它跟流水线的目的是一样的,都是希望能够并行执行多条指令),这个技术可以让CPU在一个时钟周期里面执行多个指令的不同阶段(CPU在执行一个指令时会把每个指令分解为多个微操作,一个时钟周期只能执行一个微操作),从而到达多条指令的并行执行的效果,但是流水线技术只有在指令代码执行的顺序是确定的时候才有效,而当存在分支跳转的时候,指令的执行顺序是不确定的,所以此时无法并行执行多条指令,当然现代CPU还有一种被称为分支预测的技术,它可以根据一些条件来预测分支往那个方向跳转,如果预测成功则可以继续并行执行会跳转到的分支的代码,不过如果预测失败则会执行一个回退的过程,这个会增加CPU的开销,尽管目前CPU的分支预测成功的概率还是挺高的,但离100%还是有一些差距的,有兴趣的同学可以自行搜索CPU流水线和分支预测方面的知识)
如果不考虑性能问题,那么ZEND_ADD的handler代码将如下所示(经过简化的伪代码):
int ZEND_ADD(zend_op *op1, zend_op *op2)
{
void *op1_value;
void *op2_value;
switch (op1->type) {
case IS_CV:
op1_value = read_op_as_a_cv(op1);
break;
case IS_VAR:
op1_value = read_op_as_a_var(op1);
break;
case IS_CONST:
op1_value = read_op_as_a_const(op1);
break;
case IS_TMP_VAR:
op1_value = read_op_as_a_tmp(op1);
break;
case IS_UNUSED:
op1_value = NULL;
break;
}
/* ... 对op2做同样的事情 .../
/* 对op1_value和op2_value做一些事情 (执行一个算术加法运算?) */
}
现在你要意识到我们是在设计某个OPCode的handler,这个handler可能会在执行PHP脚本的时候被调用很多次。如果每次调用这个handler时都不得不先获取它的操作数的类型,然后根据不同的类型执行不同的读取(fetch/read)代码,这显然不利于程序的性能(不是非常夸张,但仍然存在)。
对于这个问题有一个非常棒的替代方案。
还记得上面提到的PHP源码中对ZEND_ADD这个OPCode的handler的定义么:
ZEND_VM_HANDLER(1, ZEND_ADD, CONST|TMP|VAR|CV, CONST|TMP|VAR|CV)
{
USE_OPLINE
zend_free_op free_op1, free_op2;
SAVE_OPLINE();
fast_add_function(&EX_T(opline->result.var).tmp_var,
GET_OP1_ZVAL_PTR(BP_VAR_R),
GET_OP2_ZVAL_PTR(BP_VAR_R) TSRMLS_CC);
FREE_OP1();
FREE_OP2();
CHECK_EXCEPTION();
ZEND_VM_NEXT_OPCODE();
}
看看这个奇怪的函数的签名,它甚至都不符合有效C语法(因此它不可能通过C编译器的编译)。
ZEND_VM_HANDLER(1, ZEND_ADD, CONST|TMP|VAR|CV, CONST|TMP|VAR|CV)
这行代码表示ZEND_ADD的handler的第一个操作数op1可以接受CONST、TMP、VAR或者CV类型,op2也是如此。
现在我们再介绍一个神奇的东西:包含这段代码的源文件是zend_vm_def.h,这只是一个模板文件,它会被传给一个处理工具(processor),这个工具会生成每个handler的代码(符合C语言语法的程序),它会对所有操作数类型进行排列组合,然后生成专属于组合中的每一项的handler函数。
我们来算个数,op1可接受5种不同的类型,op2也可以接受5种不同的类型,那个op1和op2的类型组合就有25种情况:上面的工具会为ZEND_ADD生成25个不同的专用于处理特定类型组合的handler函数,这些函数会被写入一个文件中,这个文件会作为PHP源码的一部分被编译。
最终生成的文件名为zend_vm_execute.h,也许你现在正打算点开这个链接,不过你还是建议你三思而后行:因为它真XX的大,别怪我没提醒你噢;-)
现在继续我们算数工作,PHP5.6支持167个OPCode,假设这167个OPCode每个都有可以接受5种操作数类型的op1和op2,那么最终生成的文件会包含4175个C函数。
实际上并非每个OPCode都支持5种不同的操作数类型,所以最终生成的函数个数会小于上面的数字。例如:
ZEND_VM_HANDLER(84, ZEND_FETCH_DIM_W, VAR|CV, CONST|TMP|VAR|UNUSED|CV)
ZEND_FETCH_DIM_W(对某个组合实体(array/object)某个维度的元素进行写操作)的op1只支持两种类型:IS_VAR和IS_CV。
但是zend_vm_execute.h这个文件仍然有大概45000行的C代码,所以正如我之前所建议的,打开这个文件之前请三思,因为打开它可能需要花一点时间。
现在我们小结一下:
- zend_vm_def.h并非有效的C文件,它描述了每个OPCode的handler的特点(使用一种与C接近的自定义语法),每个handler的特点依赖于它的op1和op2的类型,每个操作数最多支持5种类型
- zend_vm_def.h会被传递给一个名为zend_vm_gen.php的PHP脚本,这个脚本位于PHP源码中,它会分析zend_vm_def.h中的特殊语法,会用到很多正则表达式匹配,最终会生成出zend_vm_execute.h这个文件
- zend_vm_def.h在编译PHP源码时不会被处理(这是很显然的)
- zend_vm_execute.h是解析zend_vm_def.h后的输出文件,它包含了符合C语法的代码,它是VM executor的心脏:每个OPCode的专有handler函数都存放在这个文件里,很显然这是一个非常重要的文件
- 当你从源码编译PHP时,PHP源码会提供一个默认的zend_vm_execute.h文件,不过如果你想修改(hack)PHP源码,例如你想添加一个新的OPCode,或者是修改一个已存在的OPCode的行为,你必须先修改(hack)zend_vm_def.h,然后再重新生成zend_vm_execute.h文件
有意思的是:PHP虚拟机的Executor是通过PHP语言自身生成的,哈哈!
我们再来看一个示例:
下面是zend_vm_def.h中定义的ZEND_ADD这个OPCode的handler:
ZEND_VM_HANDLER(1, ZEND_ADD, CONST|TMP|VAR|CV, CONST|TMP|VAR|CV)
把zend_vm_def.h这个文件传给zend_vm_en.php脚本,将会生成一个新的zend_vm_execute.h文件,这个文件中会包含这个OPCode的专有handler,它们看起来是下面这个样子:
static int ZEND_FASTCALL ZEND_ADD_SPEC_CONST_CONST_HANDLER(ZEND_OPCODE_HANDLER_ARGS) { /* handler code */ }
static int ZEND_FASTCALL ZEND_ADD_SPEC_CONST_TMP_HANDLER(ZEND_OPCODE_HANDLER_ARGS) { /* handler code */ }
static int ZEND_FASTCALL ZEND_ADD_SPEC_CONST_VAR_HANDLER(ZEND_OPCODE_HANDLER_ARGS) { /* handler code */ }
static int ZEND_FASTCALL ZEND_ADD_SPEC_CONST_CV_HANDLER(ZEND_OPCODE_HANDLER_ARGS) { /* handler code */ }
static int ZEND_FASTCALL ZEND_ADD_SPEC_TMP_CONST_HANDLER(ZEND_OPCODE_HANDLER_ARGS) { /* handler code */ }
static int ZEND_FASTCALL ZEND_ADD_SPEC_TMP_TMP_HANDLER(ZEND_OPCODE_HANDLER_ARGS) { /* handler code */ }
/* 等等...我们就不列出所有25个函数了! */所以最终到底执行哪个专有handler是根据op1和op2的类型来确定的,例如:
$a + 2; /* IS_CV + IS_CONST */
/* ZEND_ADD_SPEC_CV_CONST_HANDLER() 这个handler函数会在VM中运行 */
这个函数名是动态生成的,它的生成模式是:ZEND_{OPCODE-NAME}_SPEC_{OP1-TYPE}_{OP2-TYPE}_HANDLER()。
你现在也许会寻思:既然我们必须根据op1和op2的类型来选择专有的handler函数,那么我们岂不是还是要通过一大段switch代码来选择正确的专有handler函数,这跟之前说的使用switch会影响性能有什么差别呢?
我只能告诉你:必须有差别啊,因为操作数的类型可以在编译期解析出,所以编译器会确定在运行期该调用哪个专有handler函数,另外如果你使用了OPCode缓存的话,那编译期的解析工作也会免了。
当PHP编译器在把PHP语言写的程序编译成OPCode时,它知道每个OPCode所接受的op1和op2的类型(因为它是编译器所以它必须知道,这是它的职责)。所以PHP编译器会直接生成一个使用正确的专有handler的OPArray:在执行过程中不会存在其他的选择,不需要使用switch():在运行期直接执行OPCode的专有handler显然会更高效一些。不过如果你修改你的PHP程序,那你必须得重新编译生成一个新的OPArray,这就是OPCode缓存要解决的问题。
Ok,我们现在为何不看下这些专有handler之间的差别呢?
其实也没有什么特别之处,对于同一个OPCode的每一个专有handler,它们唯一的差别是读取op1和op2的方式。看下面的代码:
static int ZEND_FASTCALL ZEND_ADD_SPEC_CONST_CONST_HANDLER(ZEND_OPCODE_HANDLER_ARGS) /* CONST_CONST */
{
USE_OPLINE
SAVE_OPLINE();
fast_add_function(&EX_T(opline->result.var).tmp_var,
opline->op1.zv, /* fetch op1 value */
opline->op2.zv TSRMLS_CC); /* fetch op2 value */
CHECK_EXCEPTION();
ZEND_VM_NEXT_OPCODE();
}
static int ZEND_FASTCALL ZEND_ADD_SPEC_CV_CV_HANDLER(ZEND_OPCODE_HANDLER_ARGS) /* CV_CV */
{
USE_OPLINE
SAVE_OPLINE();
fast_add_function(&EX_T(opline->result.var).tmp_var,
_get_zval_ptr_cv_BP_VAR_R(execute_data, opline->op1.var TSRMLS_CC), /* fetch op1 value */
_get_zval_ptr_cv_BP_VAR_R(execute_data, opline->op2.var TSRMLS_CC) TSRMLS_CC); /* fetch op2 value */
CHECK_EXCEPTION();
ZEND_VM_NEXT_OPCODE();
}
在CONST_CONST的handler中(op1和op2都是CONST),我们直接获取这个操作数的zval值。此时不需要做任何其他事情,例如增加或者减少一个引用计数的值,或者是释放操作数的值:这个值是不可变的,只需要读取它,这样就可以收工了。
不过对于CV_CV的handler(op1和op2都是CV,编译变量),我们必须访问它们的值,增加它们的引用计数(refcount)(这是由于我们现在要用到了它们),并且为了方便以后使用而把它们的值缓存起来:_get_zval_ptr_cv_BP_VAR_R()就是做这些事情的。我们从这个函数的命名可以看出这是一个“R”读取操作:这表示只读取操作数的值,如果这个变量不存在,这个函数会产生一个notice:未定义变量(undefined variable)。对于”W“访问情况则会有些不同,如果这个变量不存在,我们只需要创建它,而不会产生任何警告或者notice,PHP不就是这么工作的么?;-)
其他信息
编译器优化(Compiler optimizations)
zend_vm_gen.php有时候会在zend_vm_execute.h中生成一些奇怪的代码。例如:
static int ZEND_FASTCALL ZEND_INIT_ARRAY_SPEC_CONST_CONST_HANDLER(ZEND_OPCODE_HANDLER_ARGS)
{
USE_OPLINE
array_init(&EX_T(opline->result.var).tmp_var);
if (IS_CONST == IS_UNUSED) {
ZEND_VM_NEXT_OPCODE();
#if 0 || IS_CONST != IS_UNUSED
} else {
return ZEND_ADD_ARRAY_ELEMENT_SPEC_CONST_CONST_HANDLER(ZEND_OPCODE_HANDLER_ARGS_PASSTHRU);
#endif
}
}
你可能已经注意到了上面的代码中的 if (IS_CONST == IS_UNUSED) 和#if 0 || IS_CONST != IS_UNUSED这两行代码,它们看起来似乎很2。
为什么会生成这么2的代码呢?这是因为用于生成专有handler的zend_vm_def.h的模板代码就是这么写的,我们来看看:
ZEND_VM_HANDLER(71, ZEND_INIT_ARRAY, CONST|TMP|VAR|UNUSED|CV, CONST|TMP|VAR|UNUSED|CV)
{
USE_OPLINE
array_init(&EX_T(opline->result.var).tmp_var);
if (OP1_TYPE == IS_UNUSED) {
ZEND_VM_NEXT_OPCODE();
#if !defined(ZEND_VM_SPEC) || OP1_TYPE != IS_UNUSED
} else {
ZEND_VM_DISPATCH_TO_HANDLER(ZEND_ADD_ARRAY_ELEMENT);
#endif
}
}
当这个OPCode生成它的所有专有handler函数时,OP1_TYPE会被替换为每个专有handler会接受的操作数的类型,所以才会生成if (IS_CONST == IS_UNUSED)这种奇怪的代码。
不过最终生成的zend_vm_execute.h是要经过C编译器编译的,C编译器会优化掉这些没用的语句,它会直接删除这些代码,所以C编译器在把它们编译为机器码时会对它们进行优化,它们会被优化成下面这个样子:
static int ZEND_FASTCALL ZEND_INIT_ARRAY_SPEC_CONST_CONST_HANDLER(ZEND_OPCODE_HANDLER_ARGS)
{
array_init(&EX_T(opline->result.var).tmp_var);
}
自定义生成的Zend VM executor
zend_vm_gen.php这个PHP脚本被于生成VM的executor,这个脚本可以接受一些参数,所以你可以通过设置这些参数来生成不同版本的executor。例如,当你在执行zend_vm_en.php时传入--without-specializer这个参数时,它会生成一个不使用专有handler的executor。这意味着每个OPCode的handler只有一个版本(不管op1和op2是什么类型),这个handler会使用一个switch()来选择op1/op2的类型,再根据不同的类型来提取它们的值。
static int ZEND_FASTCALL ZEND_ADD_HANDLER(ZEND_OPCODE_HANDLER_ARGS)
{
USE_OPLINE
zend_free_op free_op1, free_op2;
SAVE_OPLINE();
fast_add_function(&EX_T(opline->result.var).tmp_var,
get_zval_ptr(opline->op1_type, &opline->op1, execute_data, &free_op1, BP_VAR_R),
get_zval_ptr(opline->op2_type, &opline->op2, execute_data, &free_op2, BP_VAR_R) TSRMLS_CC);
FREE_OP(free_op1);
FREE_OP(free_op2);
CHECK_EXCEPTION();
ZEND_VM_NEXT_OPCODE();
}
static inline zval *_get_zval_ptr(int op_type, const znode_op *node, const zend_execute_data *execute_data, zend_free_op *should_free, int type TSRMLS_DC)
{
/* should_free->is_var = 0; */
switch (op_type) {
case IS_CONST:
should_free->var = 0;
return node->zv;
break;
case IS_TMP_VAR:
should_free->var = TMP_FREE(&EX_T(node->var).tmp_var);
return &EX_T(node->var).tmp_var;
break;
case IS_VAR:
return _get_zval_ptr_var(node->var, execute_data, should_free TSRMLS_CC);
break;
case IS_UNUSED:
should_free->var = 0;
return NULL;
break;
case IS_CV:
should_free->var = 0;
return _get_zval_ptr_cv(node->var, type TSRMLS_CC);
break;
EMPTY_SWITCH_DEFAULT_CASE()
}
return NULL;
}
为什么要这么做呢?这主要是为了便于调式以及更易于理解executor的代码。没有使用专有handler的zend_vm_execute.h文件的大小会是使用专有handler文件的十分之一。不过当你使用这个executor执行PHP程序时,它的执行效率要比使用专有handler的低10%到15%。
Zend VM executor的专有handler最开始是在PHP5.1加入的(2005)
另外一个参数是 --with-vm-kind=CALL|SWITCH|GOTO。CALL(函数调用)是它的默认值。
还记得我们之前介绍的executor中的while(1)这个循环么?为了刷新的记忆我把这段代码再贴一次(简化后的版本):
ZEND_API void execute_ex(zend_execute_data *execute_data TSRMLS_DC)
{
/* ... simplified ... */
while (1) {
int ret;
if ((ret = execute_data->opline->handler(execute_data TSRMLS_CC)) > 0) {
switch (ret) {
case 1:
EG(in_execution) = original_in_execution;
return;
case 2:
goto zend_vm_enter;
break;
case 3:
execute_data = EG(current_execute_data);
break;
default:
break;
}
}
}
zend_error_noreturn(E_ERROR, "Arrived at end of main loop which shouldn't happen");
}
上面这段代码使用了CALL策略(strategy),它会在每个OPCode的handler的最后增加execute_data->opline指针,然后再进入while(1)的下一次循环。就这样,executor可以顺序地一个OPCode接一个OPCode的执行,直到遇到ZEND_RETURN这个OPCode。
除了CALL策略外,还有其他的方式来到达顺序执行OPCode的目的。例如使用C语言中的goto语句,或者是使用switch()语句。
这就是--with-vm-kind的作用:它会控制zend_vm_gen.php生成3种使用不同方式进行流程控制的executor。我们看下使用C语言中的goto语句的情况:
ZEND_API void execute_ex(zend_execute_data *execute_data TSRMLS_DC)
{
/* ... simplified ... */
while (1) {
goto *(void**)(execute_data->opline->handler);
}
}
你会看到while(1)依旧存在,但是这次是使用goto来跳转到一个函数指针。在这种情况下,某个OPCode的handler会在处理完后增加execute_data->opline指针,这个指针会指向下一个OPCode,然后再使用goto语句跳转到下一个handler函数的入口,我们可以看下此时的ZEND_VM_NEXT_OPCODE()这个宏展开后的代码:
#define ZEND_VM_INC_OPCODE() execute_data->opline++
#define ZEND_VM_CONTINUE() goto *(void**)(OPLINE->handler) /* 这里使用了goto */
#define ZEND_VM_NEXT_OPCODE() \
CHECK_SYMBOL_TABLES() \
ZEND_VM_INC_OPCODE(); \
ZEND_VM_CONTINUE()
CALL是Zend Executor分发循环的默认策略,这是因为使用这种策略时,C编译器可以在大多数目标平台下编译出性能良好的本地机器代码。不过你可以根据你自己的平台和C编译器的特性来选择可以达到最近性能的方式,例如goto这种方式,有些CPU家族(CPU families)会为它提供专有的汇编指令。(译注:这个的意思是如果你使用goto语句,C编译器会把它编译为特定CPU上的专有汇编指令,而不是通常的JMP之类的指令,这种情况下goto的效果会更好)
Executor中的跳转(jumps)
你知道Zend VM executor怎么执行PHP脚本中的if语句吗?很简单:对于if语句生成的OPCode,它的handler函数不会使用ZEND_VM_NEXT_OPCODE()宏,这个宏只会使executor一条OPCode一条OPCode地线性执行,它不能修改executor的执行路径,所以如果要实现if或者循环跳转——我们需要能够跳转(jump)到一个特定的OPCode。
$a = 8;
if ($a == 9) {
echo "foo";
} else {
echo "bar";
}
compiled vars: !0 = $a
line #* I O op fetch ext return operands
-----------------------------------------------------------------------------------
3 0 > ASSIGN !0, 8
5 1 IS_EQUAL ~1 !0, 9
2 > JMPZ ~1, ->5
6 3 > ECHO 'foo'
7 4 > JMP ->6
8 5 > ECHO 'bar'
10 6 > > RETURN 1
注意到ZEND_JMP和ZEND_JMPZ这两个OPCode没?它们只会改变程序的控制流程(control flow):
static int ZEND_FASTCALL ZEND_JMP_SPEC_HANDLER(ZEND_OPCODE_HANDLER_ARGS)
{
USE_OPLINE
ZEND_VM_SET_OPCODE(opline->op1.jmp_addr);
ZEND_VM_CONTINUE();
}
#define ZEND_VM_SET_OPCODE(new_op) \
CHECK_SYMBOL_TABLES() \
execute_data->opline = new_op
ZEND_VM_SET_OPCODE这个宏会告诉executor的主循环不要增加opline指针——这么做只会立即执行下一个OPCode,而是将opline跳转到一个新地址(jpm_addr),这个地址保存在ZEND_JMP的handler的操作数op1中。这个地址是在编译期计算出的。
性能优化小贴士(Performance tips)
现在我要介绍几个根据OPCode来优化PHP脚本的小技巧。
实话说我并不喜欢写这些内容,因为有些人看了这些内容后总喜欢不加思考地使用这些规则,他们一般不会意识到这些小技巧不会给他们自己的那些一个页面会包含1200个SQL查询的应用带来任何实质性的改善:-p。我们需要根据具体上下文来使用这些技巧。
不过话说回来,如果你的代码中有一些迭代次数非常多的循环,那么这些小技巧还是很有用的。
echo一个字符串连接
你可能已经看到过很多这样的代码(也许也写了不少):
$foo = 'foo';
$bar = 'bar';
echo $foo . $bar;
下面是这段代码编译后生成的OPArray:
compiled vars: !0 = $foo, !1 = $bar
line #* I O op fetch ext return operands
-----------------------------------------------------------------------------------
3 0 > ASSIGN !0, 'foo'
4 1 ASSIGN !1, 'bar'
6 2 CONCAT ~2 !0, !1
3 ECHO ~2
7 4 > RETURN 1
zend引擎会连接(ZEND_CONCAT)$a和$b的值,然后把结果存到一个临时变量(~2)中,这个临时变量的值会被echo出来,然后它会被扔掉。
这几个OPCode意味着什么呢?它们意味着zend引擎即要为一个字符串分配内存空间,还要执行一个复杂的操作:字符串连接——然后再echo这个字符串,最后再把分配的内存释放掉。你可能会觉得一个这么简单的操作尽然要搞得这么复杂,何苦呢?
所以为何不把代码写成下面这个样子:
$foo = 'foo';
$bar = 'bar';
echo $foo , $bar;
compiled vars: !0 = $foo, !1 = $bar
line #* I O op fetch ext return operands
-----------------------------------------------------------------------------------
3 0 > ASSIGN !0, 'foo'
4 1 ASSIGN !1, 'bar'
6 2 ECHO !0
3 ECHO !1
7 4 > RETURN 1
看到差别了吧?在echo中使用一个逗号','是完全合法的,Zend编译器允许echo语句接受任意多个参数(以逗号分隔),并且它会为每一个参数生成一个ZEND_ECHO的OPCode。这看起来要方便多了。
此时即不用在内存中创建一个临时的缓冲区,也不需要执行字符串连接了。
下面是ZEND_CONCAT这个OPCode的handler的定义:
ZEND_VM_HANDLER(8, ZEND_CONCAT, CONST|TMP|VAR|CV, CONST|TMP|VAR|CV)
{
USE_OPLINE
zend_free_op free_op1, free_op2;
SAVE_OPLINE();
concat_function(&EX_T(opline->result.var).tmp_var,
GET_OP1_ZVAL_PTR(BP_VAR_R),
GET_OP2_ZVAL_PTR(BP_VAR_R) TSRMLS_CC);
FREE_OP1();
FREE_OP2();
CHECK_EXCEPTION();
ZEND_VM_NEXT_OPCODE();
}
你可以查看concat_function的源码,这个函数会做如下几件事情:
- 检查操作数1是否是字符串,如果不是则把它转换为字符串(重处理,heavy process)(译注:在这里我把heavy process直接翻译为“重处理”,它的意思就是要花一些时间来某个操作)
- 检查操作数2是否是字符串,如果不是则把它转换为字符串(重处理)
- 分配一个缓冲区,确定它的尺寸,然后把连接的结果拷贝到这个缓冲区中,再返回
下面是一段字符串连接的代码(出自concat_function()):
int length = Z_STRLEN_P(op1) + Z_STRLEN_P(op2);
char *buf = (char *) emalloc(length + 1);
memcpy(buf, Z_STRVAL_P(op1), Z_STRLEN_P(op1));
memcpy(buf + Z_STRLEN_P(op1), Z_STRVAL_P(op2), Z_STRLEN_P(op2));
buf[length] = 0;
ZVAL_STRINGL(result, buf, length, 0);
即使提供的两个参数都是字符串,我们也还是需要访问主存(从上面的代码来看)。这会需要执行多个CPU指令,并且在通常情况下(很不幸),这些字符串数据并不会位于CPU的缓存中(L1/L2/L3),所以CPU必须从主存(main memory)中读取这些数据。这会耗费几纳秒(通常是十几纳秒),这个开销看起来似乎也不大。不过如果是在一个拥有几千次迭代的循环中使用这种代码,那么纳秒级的执行时间将变成微秒级:这还只是一个echo语句执行时间而已。
define()和const
const关键字是从PHP5.3开始引入了,这个关键字跟define()在性能上有很大的差别。
简单概括就是:
- define()是函数调用,所以它必然会承受一些函数调用的开销
- const是一个关键字,它不会被编译成一个会产生函数调用的OPCode,所以它会比define()要更轻量一些
你应该铭记:永远不要使用define()来定义在编译期就知道其值的常量(基本上所有的常量都是如此)。
define('FOO', 'foo');
echo FOO;
line #* I O op fetch ext return operands
-----------------------------------------------------------------------------------
3 0 > SEND_VAL 'FOO'
1 SEND_VAL 'foo'
2 DO_FCALL 2 'define'
5 3 FETCH_CONSTANT ~1 'FOO'
4 ECHO ~1
6 5 > RETURN 1上面的代码从性能角度而言非常糟糕。
这篇文章不会详细介绍executor如何处理函数调用,因为这个话题太复杂了,又得写几千字才能讲清楚。不过我已经在之前的一篇blog中介绍了Zend引擎中函数调用的开销。
define()会导致函数调用,它会把常量注册到引擎中,这样之后ZEND_FETCH_CONSTANT这个OPCode就可以直接读取常量的值。
下面再看看const的情况:
const FOO = 'foo';
echo FOO;
line #* I O op fetch ext return operands
-----------------------------------------------------------------------------------
3 0 > DECLARE_CONST 'FOO', 'foo'
5 1 FETCH_CONSTANT ~0 'FOO'
2 ECHO ~0
6 3 > RETURN 1
所有跟函数调用相关(用于define())的OPCode都消失了,它们被一个更轻量级的OPCode(DECLARE_CONST)所取代。
不过对于const和define()而言,还有一些小问题,不过这都是逻辑上的问题:
- const不能声明条件常量
- const(DECLARE_CONST)不能使用任何除IS_CONST外的其他操作数类型
这意味着你不能在下面的代码中使用const,但是可以使用define():
if (foo()) {
const FOO = 'foo'; /* 编译器会禁止这种写法 */
}下面的写法也不行:
$a = 'FOO';
const $a = 'foo';
尽管const结构在性能上表现更好,但它也会影响你的代码的动态性。
动态函数调用
再重申一遍,这篇文章不会详细讲解executor中如何处理函数调用,因为这个话题非常非常复杂,一时半会也讲不清。不过在此我会介绍一些对性能不利的函数调用方式,而不会涉及太多细节。
先看一个最简单的函数调用:
function foo() { }
foo();
line #* I O op fetch ext return operands
-----------------------------------------------------------------------------------
3 0 > NOP
5 1 DO_FCALL 0 'foo'
6 2 > RETURN 1NOP表示“没有操作(No Operation)”。编译器之所以会生成这个OPCode因为一些历史原因:-)。NOP的执行时间是真正的0秒,你不用管它们(OPCache这种优化器会把它们都剔除掉)。
上面的代码只生成了一个DO_FCALL的OPCode,这个OPCode就是调用函数foo()的OPCode。好了,这个示例没什么可说的了。
我们再看一个动态函数调用:
function foo() { }
$a = 'foo';
$a();
line #* I O op fetch ext return operands
-----------------------------------------------------------------------------------
3 0 > NOP
6 1 ASSIGN !0, 'foo'
7 2 INIT_FCALL_BY_NAME !0
3 DO_FCALL_BY_NAME 0
9 4 > RETURN 1这个函数调用使用了两个OPCode,而不像之前一样只有一个,似乎开始有点不利于整体性能的感觉了(不过我们还是先看下这些OPCode的handler再下结论)。首先你要知道多出的这个OPCode(INIT_FCALL_BY_NAME)之所以会在此出现,是因为编译器在编译的时候并不知道你想调用哪个函数,因为此时函数名被保存在一个变量中了(动态函数调用)。
记住一点编译器不能解释(interpret)变量,编译器在编译时并不知道变量中保存的是什么。PHP程序中的变量会被编译为CV,根据定义它们是动态的,它们可以保存任何信息(它们可能是NULL值,或者甚至是“undefined variables”,在编译期间谁能知道呢?)。所以在这种情况下,编译器没有其他选择,除了把函数调用的准备工作和查询符号表的工作推迟到运行期进行,这不利于性能,这是因为有些本可以在编译器完成的工作,现在必须得推迟到运行期进行。
我们再看看INIT_FCALL_BY_NAME_SPEC_CV_HANDLER这个handler的部分代码(上面的示例就使用了这个handler函数):
static int ZEND_FASTCALL ZEND_INIT_FCALL_BY_NAME_SPEC_CV_HANDLER(ZEND_OPCODE_HANDLER_ARGS)
{
USE_OPLINE
zval *function_name;
call_slot *call = EX(call_slots) + opline->result.num;
char *function_name_strval, *lcname;
int function_name_strlen;
function_name = _get_zval_ptr_cv_BP_VAR_R(execute_data, opline->op2.var TSRMLS_CC);
if (EXPECTED(Z_TYPE_P(function_name) == IS_STRING)) { /* Are we a string ? */
function_name_strval = Z_STRVAL_P(function_name);
function_name_strlen = Z_STRLEN_P(function_name);
if (function_name_strval[0] == '\\') {
function_name_strlen -= 1;
lcname = zend_str_tolower_dup(function_name_strval + 1, function_name_strlen);
} else {
lcname = zend_str_tolower_dup(function_name_strval, function_name_strlen);
}
if (UNEXPECTED(zend_hash_find(EG(function_table), lcname, function_name_strlen+1, (void **) &call->fbc) == FAILURE)) {
zend_error_noreturn(E_ERROR, "Call to undefined function %s()", function_name_strval);
}
efree(lcname);
call->object = NULL;
call->called_scope = NULL;
call->num_additional_args = 0;
call->is_ctor_call = 0;
EX(call) = call;
CHECK_EXCEPTION();
ZEND_VM_NEXT_OPCODE();
} else if (IS_CV != IS_CONST && IS_CV != IS_TMP_VAR &&
EXPECTED(Z_TYPE_P(function_name) == IS_OBJECT) && /* Are we an object (closure) ? */
/* code simplified and not showed here */
} else if (IS_CV != IS_CONST &&
EXPECTED(Z_TYPE_P(function_name) == IS_ARRAY) &&
zend_hash_num_elements(Z_ARRVAL_P(function_name)) == 2) { /* Are we an array ? */
/* code simplified and not showed here */
}
if (UNEXPECTED(call->fbc == NULL)) {
zend_error_noreturn(E_ERROR, "Call to undefined method %s::%s()", ce->name, Z_STRVAL_PP(method));
}
call->num_additional_args = 0;
call->is_ctor_call = 0;
EX(call) = call;
CHECK_EXCEPTION();
ZEND_VM_NEXT_OPCODE();
} else {
if (UNEXPECTED(EG(exception) != NULL)) {
HANDLE_EXCEPTION();
}
zend_error_noreturn(E_ERROR, "Function name must be a string");
ZEND_VM_NEXT_OPCODE(); /* Never reached */
}
}
上面所有分析代码都不可能被缓存起来,因为下一次执行这段代码时,你的变量$variable_that_is_a_function_name的值可能已经改变了。
从更广泛地的角度来说,你需要记住一条常识:你使用越多PHP语言的动态特性,executor就需要做越多的工作来执行你的PHP代码,你的代码的整体性能也会越差。
这种情况对方法(method,类的方法)也同样适用,除了一点小差别外,这点差别对性能可能会有较大的影响:类在运行时可能不存在,这可能会触发自动加载(autoload
),这会带来巨大的性能差异。不过使用OPCode的缓存可以显著降低这些不利的影响。
类的延迟绑定(Delayed class binding)
现在要讨论的这个话题是蛋糕上的奶油:类和继承。
再强调一句:为了性能考虑,当在声明class A继承class B之前,你最好已经定义了B,如果没有:只会再一次增加运行时的负担。
我们来看看代码:
class Bar { }
class Foo extends Bar { }
compiled vars: none
line #* I O op fetch ext return operands
-----------------------------------------------------------------------------------
3 0 > NOP
5 1 NOP
2 NOP
6 3 > RETURN 1上面的代码没任何问题:如果你以正确的方式写代码,以正确的顺序定义类,那么编译器可以接管所有跟类声明相关的繁琐工作。你可以从上面输出的OPCode中看出executor做了什么事情没?NOP、NOP,再NOP:什么都没做(OPCache优化器甚至会删除所有的这些开销超级小的NOP)。
编译器接管了这个工作(声明一个类是一项耗费性能工作),再次强调下如果你使用OPCode缓存,那么你甚至可以根本不用再管编译期的事情了。
所以根据上面的执行情况来看,在PHP中声明类实际上是非常轻量级的工作,当然前提是你把类声明的顺序搞对:
class Foo extends Bar { }
class Bar { }
compiled vars: none
line #* I O op fetch ext return operands
-----------------------------------------------------------------------------------
3 0 > FETCH_CLASS 4 :0 'Bar'
1 DECLARE_INHERITED_CLASS '%00foo%2Ftmp%2Ffoo.php0x7f198b0c401d', 'foo'
5 2 NOP
6 3 > RETURN 1上面的代码中我们同样声明了一个类Foo,它继承自Bar,但是在编译器读取这个声明的时候,它并不知道任何关于Bar的信息。在这种情况下,为了在executor中执行Foo的代码,编译器要怎么给Foo准备内存呢?编译器什么都做不了:如果这种情况出现在动态特性不强的语言中,上面的代码会产生一个编译错误:“解析错误:无法找到类(Parse error: class not found)”,根本不会进入执行期。显然PHP的动态特性很强,所以它的编译器不会报错。
此时编译器只能再次把类的声明推迟到运行期进行(PHP允许这么做),这对于引擎来说是一件很繁琐的工作,它的繁琐之处在于要解析整个继承树(inheritence tree),并且要把所有的父类的方法添加到声明的类中,这些工作本来是可以在编译期完成的,但是在上面这个示例中是不可行的:这会给运行期增加负担,并且只要这个类的声明方式不变,这种负担会不断叠加。从性能角度来说,这种写法真是2得不行了啊!
再说一次,我们需要忍受PHP动态特性的折磨,因为它允许使用一个未经过编译的类的对象(使用自动加载(autoloaded)?)。确实这些特性让PHP看起来很灵活,很好用,但是你的机器也会为你的懒惰付出代价。不过如果你使用OPCode缓存,特别是OPCache,它们会非常有效地优化这种情况。
注意这种情况对于trais的绑定,以及接口实现也适用,在PHP内部,类/trait/接口是完全相同的结构,对它们的处理很多都是一样的。
你还没搞清楚?那我们再看一个例子:
class Foo { }
compiled vars: none
line #* I O op fetch ext return operands
-----------------------------------------------------------------------------------
3 0 > NOP
4 1 > RETURN 1上面的代码在运行的时候没有任何特殊的OPCode,就跟之前的示例一样。我们在上面的代码中加一点动态特性:
if ($a) {
class Foo { }
}
compiled vars: !0 = $a
line #* I O op fetch ext return operands
-----------------------------------------------------------------------------------
3 0 > > JMPZ !0, ->3
4 1 > DECLARE_CLASS $0 '%00foo%2Ftmp%2Ffoo.php0x7fcef3f9701d', 'foo'
5 2 > JMP ->3
6 3 > > RETURN 1你可以看到动态特性的代价:现在这个类完全是在运行期声明和解析的(ZEND_DECLARE_CLASS这个OPCode就是干这个事的),你每次运行这段代码都会进行这些处理。现在搞清楚了吧!
总结
这篇文章展示了Zend虚拟机中的核心部分:executor的代码。它是PHP源码中完成“真正”的执行PHP程序的部分:它会执行PHP脚本被转换成的每个单个任务(每个OPCode)。它是PHP源码中对PHP脚本的执行性能有最关键影响的部分,所以在设计它的时候,性能被作为第一因素进行考虑。
这也是为什么在你对软件虚拟机的设计或者是对底层程序设计并不熟悉时阅读这些代码时会困惑于这些代码为何要写成这个样子的原因,它们对你而言似乎非常复杂。对于这个问题的唯一答案就是性能。C语言是唯一可以实现这些细节层面优化的语言,至少在我所知道的语言中是如此,C代码会被直接编译为目标机器的汇编指令,现如今它的编译器已经非常成熟,大多数C编译器都已经差不多有40多年的历史了。
你要知道事实上PHP虚拟机,包括它的整个源码都已经经过了差不多20年的修改、重构和优化了,所以请相信我,如果PHP要你以某种方式才能更高效地完成某件事情,那么请接受它,这些都是经过精心设计的,而不是随机为之的。为了优化某些底层部分的性能,我们甚至会阅读不同编译器编译executor所生成的汇编代码,从中寻找哪些地方可以进一步优化,从而让编译器生成出更优化的代码(有很多技巧可以优化C编译器生成的代码)。另外Zend虚拟机中的一些关键部分甚至是直接用汇编语言写成的(不多,但还是有一些)。
当然你也可以自己玩玩它们:前提是你必须设计一个zend_extension。PHP扩展(extension)也可以做很多事情,不过如果你想玩玩executor和OPArrays,最好还是在zend_extension中搞,因为它们比起一般的PHP扩展要更强大。例如OPCache就是一个zend_extension,因为它需要对OPArray中的OPCode做很多事情,它的主要功能是优化这些OPCode(例如使用一种名为compiler passes的技术来优化掉不可到达的代码)以及缓存它们以供下次请求重用,从而防止处理每次请求时都要对编译PHP脚本进行编译。
最后插播一个小广告,我目前的主要工作是开发Blackfile性能分析器这个扩展,它可以告诉你的代码中有哪些性能问题,例如上面我所介绍的哪些会引起性能问题的代码,当然还有其他一些功能在此我就不详细介绍了,有兴趣的同学可以自己去看看;-)